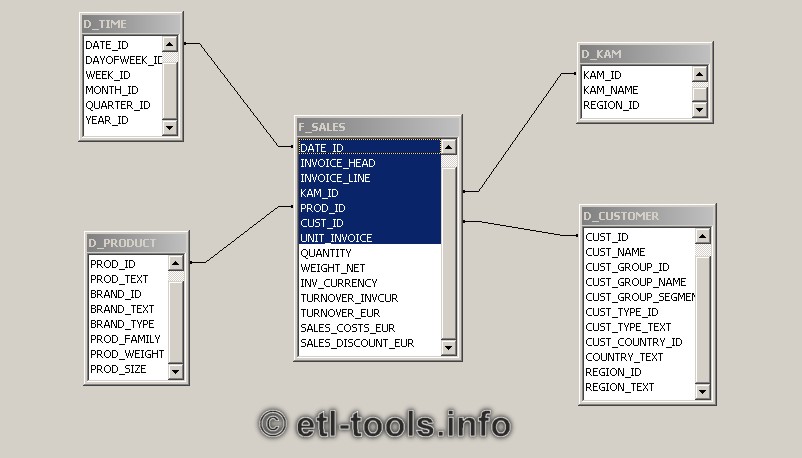
I'm building a data warehouse. Each fact has it's timestamp. I need to create reports by day, month, quarter but by hours too. Looking at the examples I see that dates tend to be saved in dimension tables. 
(source: etl-tools.info)
{kind=link}
But I think, that it makes no sense for time. The dimension table would grow and grow. On the other hand JOIN with date dimension table is more efficient than using date/time functions in SQL.
What are your opinions/solutions ?
(I'm using Infobright)