I have written the following code with the phrase extraction algorithm for SMT.
# -*- coding: utf-8 -*-
def phrase_extraction(srctext, trgtext, alignment):
"""
Phrase extraction algorithm.
"""
def extract(f_start, f_end, e_start, e_end):
phrases = set()
# return { } if f end == 0
if f_end == 0:
return
# for all (e,f) ∈ A do
for e,f in alignment:
# return { } if e < e start or e > e end
if e < e_start or e > e_end:
return
fs = f_start
# repeat-
while True:
fe = f_end
# repeat-
while True:
# add phrase pair ( e start .. e end , f s .. f e ) to set E
trg_phrase = " ".join(trgtext[i] for i in range(fs,fe))
src_phrase = " ".join(srctext[i] for i in range(e_start,e_end))
phrases.add("\t".join([src_phrase, trg_phrase]))
fe+=1 # fe++
# -until fe aligned
if fe in f_aligned or fe > trglen:
break
fs-=1 # fe--
# -until fs aligned
if fs in f_aligned or fs < 0:
break
return phrases
# Calculate no. of tokens in source and target texts.
srctext = srctext.split()
trgtext = trgtext.split()
srclen = len(srctext)
trglen = len(trgtext)
# Keeps an index of which source/target words are aligned.
e_aligned = [i for i,_ in alignment]
f_aligned = [j for _,j in alignment]
bp = set() # set of phrase pairs BP
# for e start = 1 ... length(e) do
for e_start in range(srclen):
# for e end = e start ... length(e) do
for e_end in range(e_start, srclen):
# // find the minimally matching foreign phrase
# (f start , f end ) = ( length(f), 0 )
f_start, f_end = trglen, 0
# for all (e,f) ∈ A do
for e,f in alignment:
# if e start ≤ e ≤ e end then
if e_start <= e <= e_end:
f_start = min(f, f_start)
f_end = max(f, f_end)
# add extract (f start , f end , e start , e end ) to set BP
phrases = extract(f_start, f_end, e_start, e_end)
if phrases:
bp.update(phrases)
return bp
srctext = "michael assumes that he will stay in the house"
trgtext = "michael geht davon aus , dass er im haus bleibt"
alignment = [(0,0), (1,1), (1,2), (1,3), (2,5), (3,6), (4,9), (5,9), (6,7), (7,7), (8,8)]
phrases = phrase_extraction(srctext, trgtext, alignment)
for i in phrases:
print i
The phrase extraction algorithm from Philip Koehn's Statistical Machine Translation book, page 133 is as such:
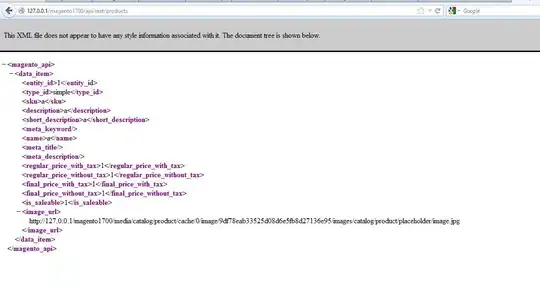
And the desired output should be:
However with my code, I am only able to get these output:
michael assumes that he will stay in the - michael geht davon aus , dass er im haus
michael assumes that he will stay in the - michael geht davon aus , dass er im haus bleibt
Does anyone spot what is wrong with my implementation?
The code does extract phrases but it's not the complete desired output as shown with the translation table above: