I tried to design a data structure for easy and fast querying (delete, insert an update speed does not really matter for me).
The problem: transitive relations, one entry could have relations through other entries whose relations I don't want to save separately for every possibility.
Means--> I know that Entry-A is related to Entry-B and also know that Entry-B is related to Entry-C, even though I don't know explicitly that Entry-A is related to Entry-C, I want to query it.
What I think the solution is:
Eliminating the transitive part when inserting, deleting or updating.
Entry:
id
representative_id
I would store them as sets, like group of entries (not mysql set type, the Math set, sorry if my English is wrong). Every set would have a representative entry, all of the set elements would be related to the representative element.
A new insert would insert the Entry and set the representative as itself.

If the newly inserted entry should be connected to another, I simply set the representative id of the newly inserted entry to the referred entry's rep.id.
Attach B to A
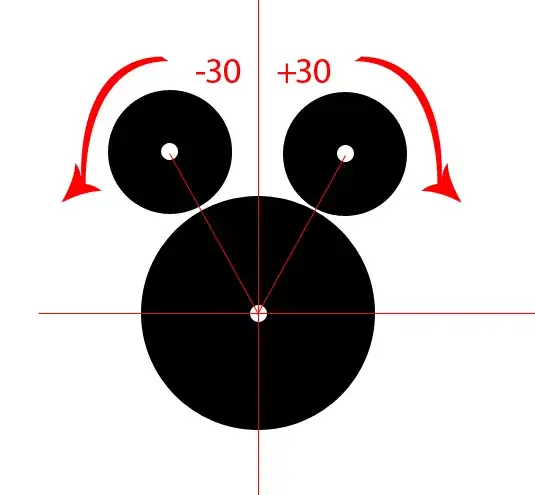
It doesn't matter, If I need to connect it to something that is not a representative entry, It would be the same, because every entry in the set would have the same rep.id.
Attach C to B
Detach B-C: The detached item would have become a representative entry, meaning it would relate to itself.
Detach B-C and attach C to X
Deletion: If I delete a non-representative entry, it is self explanatory. But deleting a rep.entry is harder a bit. I need to chose a new rep.entry for the set and set every set member's rep.id to the new rep.entry's rep.id.
So, delete A in this:
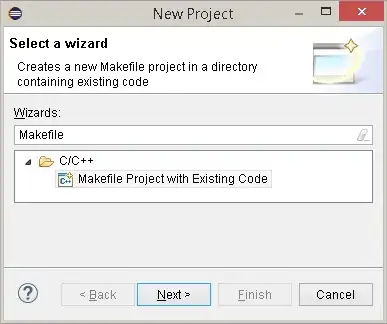
Would result this:
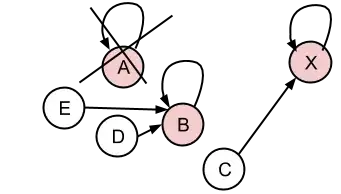
What do you think about this? Is it a correct approach? Am I missing something? What should I improve?
Edit: Querying: So, If I want to query every entry that is related to an certain entry, whose id i know:
SELECT *
FROM entries a
LEFT JOIN entries b ON (a.rep_id = b.rep_id)
WHERE a.id = :id
SELECT * FROM AlkReferencia
WHERE rep_id=(SELECT rep_id FROM AlkReferencia
WHERE id=:id);
About the application that requires this:
Basically, I am storing vehicle part numbers (references), one manufacturer can make multiple parts that can replace another and another manufacturer can make parts that are replacing other manufacturer's parts.
Reference: One manufacturer's OEM number to a certain product.
Cross-reference: A manufacturer can make products that objective is to replace another product from another manufacturer.
I must connect these references in a way, when a customer search for a number (doesn't matter what kind of number he has) I can list an exact result and the alternative products.
To use the example above (last picture): B, D and E are different products we may have in store. Each one has a manufacturer and a string name/reference (i called it number before, but it can be almost any character chain). If I search for B's reference number, I should return B as an exact result and D,E as alternatives.
So far so good. BUT I need to upload these reference numbers. I can't just migrate them from an ALL-IN-ONE database. Most of the time, when I upload references I got from a manufacturer (somehow, most of the time from manually, but I can use catalogs too), I only get a list where the manufacturer tells which other reference numbers point to his numbers.
Example.:
Asas filter manufacturer, "AS 1" filter has these cross references (means, replaces these):
GOLDEN SUPER --> 1
ALFA ROMEO --> 101000603000
ALFA ROMEO --> 105000603007
ALFA ROMEO --> 1050006040
RENAULT TRUCKS (RVI) --> 122577600
RENAULT TRUCKS (RVI) --> 1225961
ALFA ROMEO --> 131559401
FRAD --> 19.36.03/10
LANDINI --> 1896000
MASSEY FERGUSON --> 1851815M1
...
It would took ages to write all of the AS 1 references down, but there is many (~1500 ?). And it is ONE filter. There is more than 4000 filter and I need to store there references (and these are only the filters). I think you can see, I can't connect everything, but I must know that Alfa Romeo 101000603000 and 105000603007 are the same, even when I only know (AS 1 --> alfa romeo 101000603000) and (as 1 --> alfa romeo 105000603007).
That is why I want to organize them as sets. Each set member would only connect to one other set member, with a rep_id, that would be the representative member. And when someone would want to (like, admin, when uploading these references) attach a new reference to a set member, I simply INSERT INTO References (rep_id,attached_to_originally_id,refnumber) VALUES([rep_id of the entry what I am trying to attach to],[id of the entry what I am trying to attach to], "16548752324551..");
Another thing: I don't need to worry about insert, delete, update speed that much, because it is an admin task in our system and will be done rarely.