I recently came across a situation in a large dataset whereby one of my groupby series contained a few np.nan values. This causes the observation to be dropped from the results table. In a high dimensional case (>100,000 lines) this can be sometimes tricky to identify and this results in systematic loss of data. I have now become a lot more focused on my groupby items and use the minimum index information to identify unique cases prior to sum().
A simple example:
import pandas as pd
import numpy as np
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux'],
[np.nan, np.nan, 'one', 'two',
'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
np.random.seed(1234)
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
produces the following DataFrame
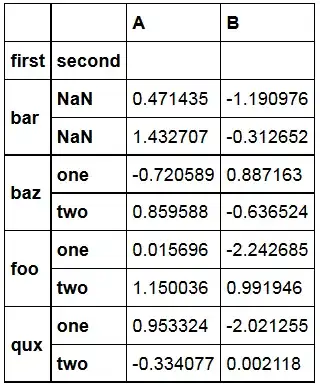
When doing GroupBy Operations
df2 = df.reset_index()
df2.groupby(['first', 'second']).sum()
#OR
df.groupby(level=['first', 'second']).sum()
We get the resulting DataFrame
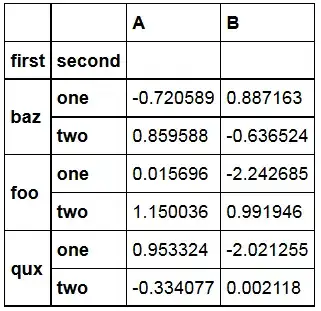
This makes good sense from a default perspective (due to incomplete information) but it would be nice to have the option not to discard bar and leave the data as is, which in this case would return the original dataframe.
This situation arose in my data because I had a redundant index item that didn't vary at the lower levels of a MultiIndex so I didn't think it would mater (as it was nice to retain in the data set as a different representation of another index item: It was FullCountryName and ISO3C code), however I found that because it wasn't defined in one country case it therefore dropped that country from the resulting dataframe (without any warnings).
Is there a way to achieve this outcome?
Perhaps a warning should be issued in the event of dropping a group due to the presence of np.nan at any level.
Update
This probably makes it clearer as an example:
import pandas as pd
import numpy as np
tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
'foo', 'foo', 'qux', 'qux',],
['one', 'two', 'one', 'two',
'one', 'two', 'one', 'two'],
[np.nan, np.nan, 'one', 'two',
'one', 'two', 'one', 'two']]))
index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second', 'third'])
np.random.seed(1234)
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
produces the following dataframe

then
df.groupby(level=['first', 'second', 'third']).sum()
produces:

where the third level doesn't matter in the uniqueness of the groupby.