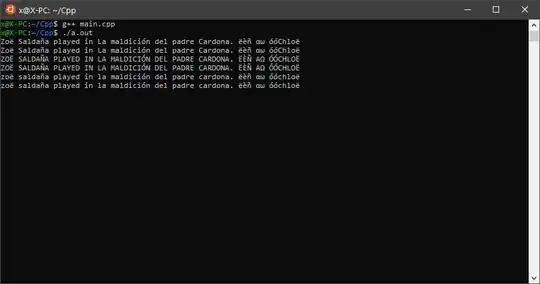
Finally I got it all sorted out in all my applications. Actually the issues mlet down to 3 different reasons and I will list all of them below so that this findings of mine could help people in the future.
Reason 1: Incorrect encoding of user created file.
This actually was the problem with the application I posted about in the question. The problem was that the encoding of the insert script I used for introducing the values in the database was "UTF8 without BOM". I converted this encoding to "UTF8" using Notepad++ and reinserted the values in the database and the issue was resolved. Thanks to @user3249477 for pointing me to thinking in this direction. By the way "UTF8 without BOM" seems to be the default encoding Eclipse uses when creating URF8 files, so take care!
Reason 2: Incorrect encoding of generated file.
The problem of reason 1, pointed me to what to think for in some of the other cases I was facing. In one application of mine I am provided with raw data that I insert in my backend database using simple Java application. The problem there turned out to be that I was passing through intermediate format, files stored on the file system that ?I used to verify I interpretted the raw data correctly. I noticed that these files were also created "UTF8 without BOM". I used this code to write to these files:
BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream(outputFilePath));
writer = new BufferedWriter(new OutputStreamWriter(outputStream, STRING_ENCODING));
writer.append(string);
Which I changed to:
BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream(outputFilePath));
writer = new BufferedWriter(new OutputStreamWriter(outputStream, STRING_ENCODING));
// prepending a bom
writer.write('\ufeff');
writer.append(string);
Following the prescriptions from this answer. This line I add basically made all the intermediate files be encoded in "UTF8" with BOM and resolved my encoding issues.
Reason 3: Incorrect parsing of HTTP responses
The last issue I encountered in few of my applications was that I was not interpretting the UTF8 http responses correctly. I used to have the following code:
HttpResponse response = httpClient.execute(host, request, (HttpContext) null);
String responseBody = null;
responseBody = IOHelper.getInputStreamContents(responseStream);
Where IOHelper is an util I have written myself and reads stream contents to String. I replaced this code with the already provided method in the Android API:
HttpResponse response = httpClient.execute(host, request, (HttpContext) null);
String responseBody = null;
if (response.getEntity() != null) {
responseBody = EntityUtils.toString(response.getEntity(), HTTP.UTF_8);
}
And this fixed the encoding issues I was having with HTTP responses.
As conclusion I can say that one needs to take special care of BOM / without BOM strings when using UTF8 encoding in Android. I am very happy I learnt so many new things during this investigation.