I have a simple toy example that seems to disagree with the garbage collector on what data structures can be reclaimed (aka memory leak). I am not trying to come up with more memory efficient versions of this algorithm (a good collection of better algorithms is here: Haskell Wiki - Prime numbers, rather an explanation why the garbage collector is not identifying the old, out of scope and unused portions of the list to reclaim that memory.
The code is here:
import Data.List (foldl')
erat' :: (Integer, Bool) -> [(Integer,Integer)] -> [(Integer,Integer)]
erat' (c,b) ((x,y):xs)
| c < x = (x,y) : erat' (c,b) xs
| c == x = (x+y,y) : erat' (c,True) xs
| c > x = (x+y,y) : erat' (c,b) xs
erat' (c,b) []
| b = []
| otherwise = [(c,c)]
erat :: [Integer] -> [(Integer,Integer)]
erat = foldl' (\a c -> erat' (c,False) a) []
primes :: Integer -> [Integer]
primes n = map snd $ erat [2..n]
In essence, calling primes with a positive integer will return a list of all prime numbers up to and including that number. A list of pairs of primes and their high water mark multiple is passed to erat', together with a pair including a candidate and a boolean (False for prime and True for non-prime). Every non-recursive call to erat' will pass a new list, and I would expect that the output would contain, at most, certain shared cells from the beginning of the list up to the point of the first change.
As soon as the modified cells in the list passed to erat' come out of scope, the memory should be flagged to be recovered, but as you can see when you try calling primes with a large enough number (1,000,000, for example), the memory utilization can quickly spike to tens of gigabytes.
Now, the question is: why is this happening? Shouldn't the generational garbage collector detect dereferenced list cells to reclaim them? And, shouldn't it be fairly easy for it to detect that they don't have references because:
a) nothing can have references from data structures older than itself; b) there cannot be newer references because those cells/fragments are not even part of a referenceable data structure anymore, since it came out of scope?
Of course, a mutable data structure would take care of this, but I feel like resorting to mutability in a case like this is dropping some of the theoretical principles for Haskell on the floor.
Thanks to the people that commented (particularly Carl), I modified the algorithm slightly to add strictness (and the optimization of starting crossing the square of the new prime, since lower multiples will be crossed by multiples of lower primes too).
This is the new version:
import Data.List (foldl')
erat' :: (Integer, Bool) -> [(Integer,Integer)] -> [(Integer,Integer)]
erat' (c,b) ((x,y):xs)
| c < x = x `seq` (x,y) : erat' (c,b) xs
| c == x = x `seq` (x+y,y) : erat' (c,True) xs
| c > x = x `seq` (x+y,y) : erat' (c,b) xs
erat' (c,b) []
| b = []
| otherwise = [(c*c,c)] -- lower multiples would be covered by multiples of lower primes
erat :: [Integer] -> [(Integer,Integer)]
erat = foldl' (\a c -> erat' (c,False) a) []
primes :: Integer -> [Integer]
primes n = map snd $ erat [2..n]
The memory consumption seems to still be quite significant. Are there any other changes to this algorithm that could help reduce the total memory utilization?
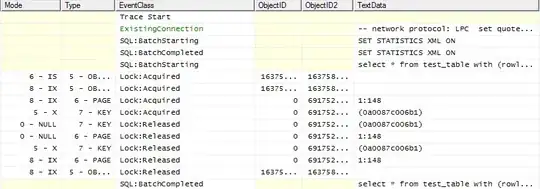
Since Will pointed out that I didn't provide full statistics, these are the numbers for a run of the updated version of primes listed just above, with 100000 as the parameter:

And after applying the changes that Will proposed, the memory usage is now down considerably. See, for example, on a run of primes for 100000 again:
And last, this is the final code after the proposed changes were incorporated:
import Data.List (foldl')
erat'' :: (Integer, Bool) -> [(Integer,Integer)] -> [(Integer,Integer)]
erat'' (c,b) ((x,y):xs)
| c < x = (x, y) : if x==y*y then (if b then xs
else xs++[(c*c,c)])
else erat'' (c,b) xs
| c == x = (x+y,y) : if x==y*y then xs
else erat'' (c,True) xs
| c > x = (x+y,y) : erat'' (c,b) xs
erat'' (c,True) [] = []
erat'' (c,False) [] = [(c*c,c)]
primes'' :: Integer -> [Integer]
primes'' n = map snd $ foldl' (\a c -> (if null a then 0 else
case last a of (x,y) -> y) `seq` erat'' (c,False) a) [] [2..n]
And finally a run for 1,000,000 to have a feeling for performance in this new version: