I'd like to write a regular expression for following type of strings in Pyhton:
1 100
1 567 865
1 474 388 346
i.e. numbers separated from thousand. Here's my regexp:
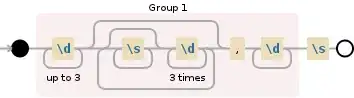
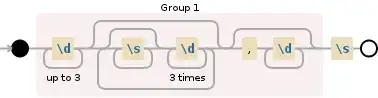
r"(\d{1,3}(?:\s*\d{3})*)
and it works fine. However, I also wanna parse
1 100,34848
1 100 300,8
19 328 383 334,23499
i.e. separated numbers with decimal digits. I wrote
rr=r"(\d{1,3}(?:\s*\d{3})*)(,\d+)?\s
It doesn't work. For instance, if I make
sentence = "jsjs 2 222,11 dhd"
re.findall(rr, sentence)
[('2 222', ',11')]
Any help appreciated, thanks.