In Javascript, there are a variety of ways to allow for inheritance of methods. Below is a hybrid example using a few of the approaches:
A = {
name: 'first',
wiggle: function() { return this.name + " is wiggling" },
shake: function() { return this.name + " is shaking" }
}
B = Object.create(A)
B.name = 'second'
B.bop = function() { return this.name + ' is bopping' }
C = function(name) {
obj = Object.create(B)
obj.name = name
obj.crunk = function() { return this.name + ' is crunking'}
return obj
}
final = new C('third')
This gives me the following inheritance hierarchy.
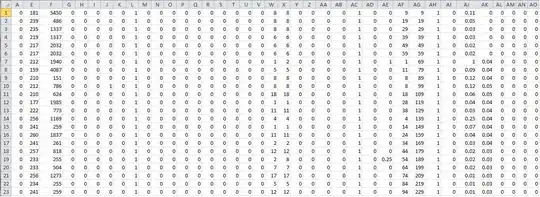
One of the important things to notice is the name property for each object. When running a method, even one far down the prototype chain, the local context defined by the this keyword ensures that the localmost property/variable is used.
I've recently moved on to Python but I'm having trouble understanding how subclasses access superclass methods, and likewise how variable scoping / object properties work.
I had created a Spider in Scrapy that (quite successfully) scraped 2000+ pages on a single domain and parsed them into a format I need. Lots of the helpers where just functions within the main parse_response method, which I could use directly on the data. The original spider looked something like this:
from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor
from spider_scrape.items import SpiderItems
class ScrapeSpider(CrawlSpider):
name = "myspider"
allowed_domains = ["domain.com.au"]
start_urls = ['https://www.domain.com.au/']
rules = (Rule(SgmlLinkExtractor(allow=()),
callback="parse_items",
follow=True), )
def parse_items(self, response):
...
The callback function parse_items contains the logic that deals with the response for me. When I generalised everything, I ended up with the following (with the intent to use this on multiple domains):
#Base
class BaseSpider(CrawlSpider):
"""Base set of configuration rules and helper methods"""
rules = (Rule(LinkExtractor(allow=()),
callback="parse_response",
follow=True),)
def parse_response(self, response):
...
def clean_urls(string):
"""remove absolute URL's from hrefs, if URL is form an external domain do nothing"""
for domain in allowed_domains:
string = string.replace('http://' + domain, '')
string = string.replace('https://' + domain, '')
if 'http' not in string:
string = "/custom/files" + string
return string
#Specific for each domain I want to crawl
class DomainSpider(BaseSpider):
name = 'Domain'
allowed_domains = ['Domain.org.au']
start_urls = ['http://www.Domain.org.au/'
,'http://www.Domain.org.au/1']
When I ran this via the Scrapy command line, I had the following error in the console:

After some testing, changing the list comprehension to this caused it to work: for domain in self.allowed_domains:
All good, that seems mighty similar to the this keyword in Javascript - I'm using properties of the object to get the values. There are many more variables/properties that will hold the required XPath expressions for the scrape:
class DomainSpider(BaseSpider):
name = 'Domain'
page_title = '//title'
page_content = '//div[@class="main-content"]'
Changing the other parts of the Spider to mimic that of the allowed_domains variable, I received this error:
I tried setting the property differently in a few ways, including using self.page_content and/or an __init__(self) constructor with no success but different errors.
I'm completely lost what is happening here. The behaviour I expect to happen is:
- When I run the
scrapy crawl <spider name>from the terminal, it instantiates the DomainSpider class - Any class constants in that class become available to all methods that it is has inherited, similar to Javascript and its
thiskeyword - Any class constants from its super class(es) are ignored due to context.
If someone could
- Explain the above to me
- Point me to something more meaty than LPTHW but not TDD with Python that would be amazing.
Thanks in advance.