I have a list of several paragraph tags. Each is without any attributes e.g.
<p>First paragraph</p>
<p>Second paragraph</p>
<p>Third paragraph</p>
My goal is to find the last opening <p> tag – no matter if I only have a single paragraph or ten. I always want the last paragraph opening tag.
With
/<p>/
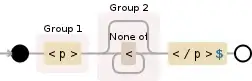
I get the first paragraph tag. I thought $ inverts the search direction from left-to-right to right-to-left. So basically
/<p>$/
should return the opening paragraph tag for the third paragraph from my example above; but the regex finds nothing at all.
So how to best target the last paragraph?