To describe my query problem, the following data is helpful:
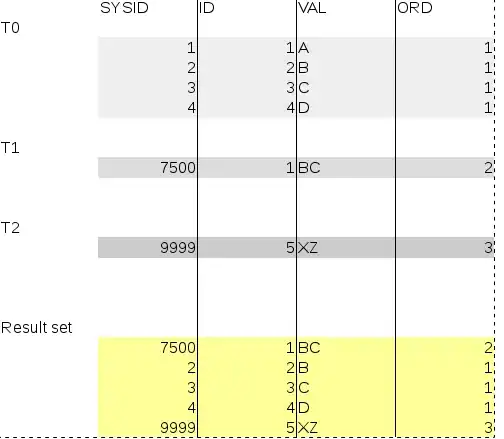
A single table contains the columns ID (int), VAL (varchar) and ORD (int)
The values of VAL may change over time by which older items identified by ID won't get updated but appended. The last valid item for ID is identified by the highest ORD value (increases over time).
T0, T1 and T2 are points in time where data got entered.
- How do I get in an efficient manner to the Result set?
A solution must not involve materialized views etc. but should be expressible in a single SQL-query. Using Postgresql 9.3.