A) This one is most readable and performant if you have many items with same id:
scala> list.groupBy(_("id")).mapValues(_.map(_("value").asInstanceOf[Int]).sum)
res14: scala.collection.immutable.Map[Any,Int] = Map(D -> 60, A -> 25, C -> 4, B -> 10)
You can also use list.groupBy(_("id")).par... as well. It will work faster only if you have many elements with same key, otherwise it will be extrimely slow.
Otherwise, changing thread's context itself will make .par version slower, as map(_"value").sum (your nested map-reduce) may be faster than switching between threads. If N = count of cores in the system, your map-reduce should be N times slower to benefit from par, roughly speaking of course.
B) So, if parallelizing didn't work so well (it's better to check that with performance tests) you can just "reimplement" groupBy in specialized way:
val m = scala.collection.mutable.Map[String, Int]() withDefaultValue(0)
for (e <- list; k = e("id").toString) m.update(k, m(k) + e("value").asInstanceOf[Int])
C) The most parallelized option is:
val m = new scala.collection.concurrent.TrieMap[String, Int]()
for (e <- list.par; k = e("id").toString) {
def replace = {
val v = m(k)
m.replace(k, v, v + e("value").asInstanceOf[Int]) //atomic
}
m.putIfAbsent(k, 0) //atomic
while(!replace){} //in case of conflict
}
scala> m
res42: scala.collection.concurrent.TrieMap[String,Int] = TrieMap(B -> 10, C -> 4, D -> 60, A -> 25)
D) The most parallelized in functional style (slower as merging maps every time, but best for distributed map-reduce without shared memory), using scalaz semigroups:
import scalaz._; import Scalaz._
scala> list.map(x => Map(x("id").asInstanceOf[String] -> x("value").asInstanceOf[Int]))
.par.reduce(_ |+| _)
res3: scala.collection.immutable.Map[String,Int] = Map(C -> 4, D -> 60, A -> 25, B -> 10)
But it will be more performant only if you use some more complex aggregation than "+".
So let's do simple performance testing:
def time[T](n: Int)(f: => T) = {
val start = System.currentTimeMillis()
for(i <- 1 to n) f
(System.currentTimeMillis() - start).toDouble / n
}
It's done in Scala 2.12 REPL with JDK8 on MacBook Pro 2.3 GHz Intel Core i7. Every test launched two times - first to warm-up the JVM.
1) For your input collection and time(100000){...}, from slowest to fastest:
`par.groupBy.par.mapValues` = 0.13861 ms
`groupBy.par.mapValues` = 0.07667 ms
`most parallelized` = 0.06184 ms
`scalaz par.reduce(_ |+| _)` = 0.04010 ms //same for other reduce-based implementations, mentioned here
`groupBy.mapValues` = 0.00212 ms
`for` + `update` with mutable map initialization time = 0.00201 ms
`scalaz suml` = 0.00171 ms
`foldLeft` from another answer = 0.00114 ms
`for` + `update` without mutable map initialization time = 0.00105
So, foldLeft from another answer seems to be the best solution for your input.
2) Let's make it bigger
scala> val newlist = (1 to 1000).map(_ => list).reduce(_ ++ _)
Now with newList as input and time(1000){...}:
`scalaz par.reduce(_ |+| _)` = 1.422 ms
`foldLeft`/`for` = 0.418 ms
`groupBy.par.mapValues` = 0.343 ms
And it's better to choose groupBy.par.mapValues here.
3) Finally, let's define another aggregation:
scala> implicit class RichInt(i: Int){ def ++ (i2: Int) = { Thread.sleep(1); i + i2}}
defined class RichInt
And test it with list and time(1000):
`foldLeft` = 7.742 ms
`most parallelized` = 3.315 ms
So it's better to use most parallelized version here.
Why reduce is so slow:
Let's take 8 elements. It produces a calculation tree from leafs [1] + ... + [1] to root [1 + ... + 1]:
time(([1] + [1]) + ([1] + [1]) + ([1] + [1]) + ([1] + [1])
=> ([1 +1] + [1 +1]) + ([1 + 1] + [1 + 1])
=> [1 + 1 + 1 + 1] + [1 + 1 + 1 + 1])
= (1 + 1 + 1 + 1) + (2 + 2) + 4 = 12
time(N = 8) = 8/2 + 2*8/4 + 4*8/8 = 8 * (1/2 + 2/4 + 4/8) = 8 * log2(8)/ 2 = 12
Or just:
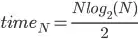
Of course this formula works only for numbers that are actually powers of 2. Anyway, the complexity is O(NlogN), which is slower than foldLeft's O(N). Even after parallelization it becomes just O(N) so this implementation can be used only for Big Data's distributed Map-Reduce, or simply saying when you have no enough memory and are storing your Map in some cache.
You may notice that it's parallelizing better than other options for your input - that's just because for 6 elements it's not so slow (almost O(1) here) - and you do only one reduce call - when other options are grouping data before or just creating more threads, which leads to more "thread switching" overhead. Simply saying, reduce creates less threads here. But if you have more data - it doesn't work of course (see experiment 2).