let's say I'm building a compiler and I want the lexical analyzer to recognize integers of the C language, can I specify for example that the integer should be between –2,147,483,648 and 2,147,483,647 that a long integer can be 64 bits? I feel that my question is stupid but I want to know if it's doable... thanks
Asked
Active
Viewed 390 times
2
-
2Not with a regular expression. – user207421 Mar 08 '15 at 23:46
-
The job of the lexer is only to segment and identify the parts of your source code, the validation of ranges is not its job, let this job to the parser. – Casimir et Hippolyte Mar 09 '15 at 01:07
2 Answers
5
Short answer
Yes that can be done, but you should not do that!
Spoiler alert: you should better be using strtol, and I'm telling you why in the long answer.
Long answer
it can be done using a weirdly crafted regexp (the worst one being a regexp with the list of all integers between MIN and MAX), but you do not want to do such a thing.
This is because such a task would mean a massive processing for the regexp, whereas that test can be done in a very little processing in your favorite language (consider the following as pseudocode):
if (str_to_int(s) > CMIN && str_to_int(s) < CMAX)
Well, actually you might tell me "but if it's an int, it will overflow!". But there are technics to detect that:
and none of them is using a regex!
But anyway, you don't need to go into so much trouble, when there's a function already baked in the C standard library that does that job for you: the strtol function! Quoting the manual:
The strtol() function returns the result of the conversion, unless the value would underflow or overflow. If an underflow occurs, strtol() returns LONG_MIN. If an overflow occurs, strtol() returns LONG_MAX. In both cases, errno is set to ERANGE. Precisely the same holds for strtoll() (with LLONG_MIN and LLONG_MAX instead of LONG_MIN and LONG_MAX).
Why would it be massive? It's because a regexp is an automaton looking at a stream of characters. When there's a match, you move along the automaton. Basically, you'd need to:
- match any string of 10 characters, or 11 only if it starts with a
- - that contains only digits,
- that if it starts with a
2, can only be followed by0or1, - that if it starts with a
2, followed by a1, can only be followed by0,1,2,3or4 - that if it starts with a
2, followed by a1and then a4, can only be followed by a1,2,3,4…7 - …
- if it starts with a
2, folowed by … and ends with a7, but if it started with a-, and then a2, it needs to end with a6(so basically you have to copy all the previous conditions into another subgraph that ends with that) - and for any other character it's a match.
That would look a bit like the following:
^(
(
\d|\d\d|\d\d\d|\d\d\d\d|\d\d\d\d\d|\d\d\d\d\d\d|
\d\d\d\d\d\d\d|\d\d\d\d\d\d\d\d|\d\d\d\d\d\d\d\d\d|
[0-2][0-1][0-4][0-7][0-4][0-8][0-3][0-6][0-4][0-8]
)|
-(
\d|\d\d|\d\d\d|\d\d\d\d|\d\d\d\d\d|\d\d\d\d\d\d|
\d\d\d\d\d\d\d|\d\d\d\d\d\d\d\d|\d\d\d\d\d\d\d\d\d|
[0-2][0-1][0-4][0-7][0-4][0-8][0-3][0-6][0-4][0-7]
)
)$
which is represented visually by the following automaton (click on the image to play with it):
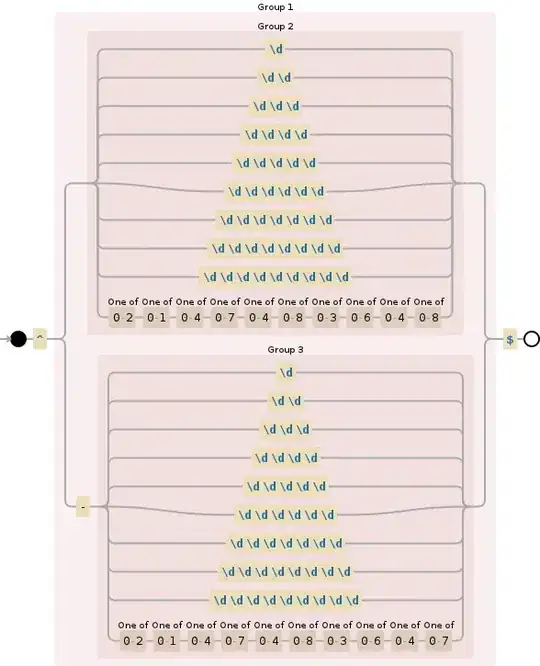
I'm not sure how correct that would be, because I might have missed edge cases, but I hope I made it clear how it compares with doing it in your favorite language. If you actually parse such a huge automaton, it will:
- burn CPU time,
- burning electricity,
- burning (fuel|coal|gaz|uranium),
- polluting the planet,
- killing a baby seal
all that instead of doing something that can be done in an operation being 1/100th of the complexity of doing the same thing using a regexp.

So if you don't want to kill a baby seal because of bad programming, don't use a regexp for something it hasn't been designed for.
Resources
To better understand what that is an automaton, how regexps are working, when is it a good idea to use and when it's a baby seal killing one, I can only advice you to look at the following courses:
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-045j-automata-computability-and-complexity-spring-2011/lecture-notes/MIT6_045JS11_lec04.pdf
- http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-005-elements-of-software-construction-fall-2011/lecture-notes/MIT6_005F11_lec05.pdf
- http://www.saylor.org/site/wp-content/uploads/2012/01/CS304-2.1-MIT.pdf
- Another answer on the topic: How to find all possible regex matches in python?
- great answer about edge case of
strtol: Does strtol("-2147483648", 0, 0) overflow if LONG_MAX is 2147483647?
Here's the visualization of @Andie2302's answer:
-\b(?:
214748364[0-8]|21474836[0-3][0-9]|2147483[0-5][0-9]{2}|
214748[0-2][0-9]{3}|21474[0-7][0-9]{4}|2147[0-3][0-9]{5}|
214[0-6][0-9]{6}|21[0-3][0-9]{7}|20[0-9]{8}|1[0-9]{9}|
[1-9][0-9]{1,8}|[0-9]|-0
)\b|
\b(?:
214748364[0-7]|21474836[0-3][0-9]|2147483[0-5][0-9]{2}|
214748[0-2][0-9]{3}|21474[0-7][0-9]{4}|2147[0-3][0-9]{5}|
214[0-6][0-9]{6}|21[0-3][0-9]{7}|20[0-9]{8}|1[0-9]{9}|
[1-9][0-9]{1,8}|[0-9]|-0
)\b
through its matching automaton:
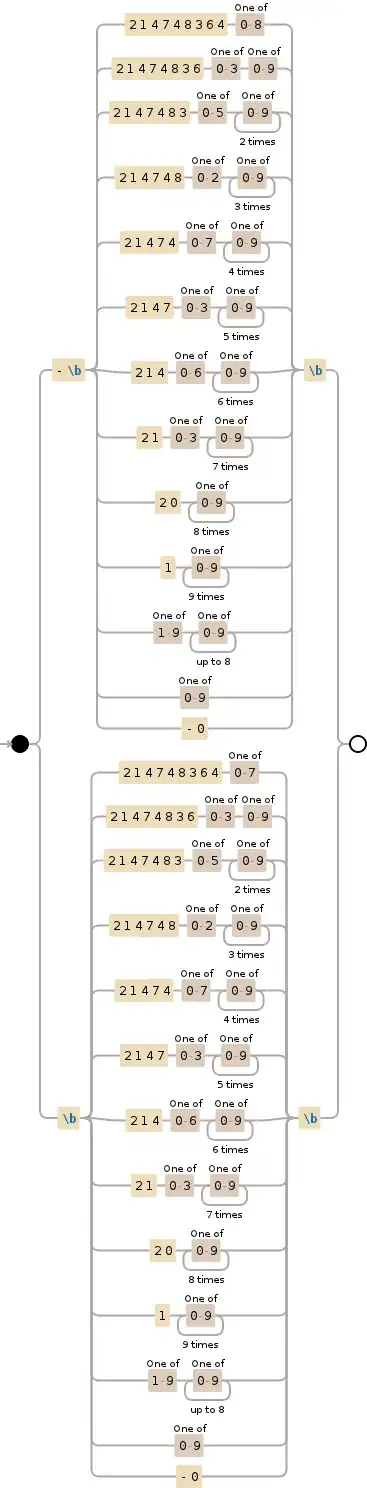
Still not convinced?
HTH
-
1Instead of `\d|\d\d|\d\d\d|` etc., wouldn’t simply `\d{1,9}` achieve the same result? – Sebastian Simon Mar 09 '15 at 00:14
-
indeed, but all in all, `\d{0,9}` is just hiding the states of the automaton, my point is to prove how massive is building an automaton for such a simple task. – zmo Mar 09 '15 at 00:15
-
Your regex is wrong: https://regex101.com/r/pR2gS1/1. It fails to match 2147483549 or 1234567890. (I agree with the point in your answer, though) – nhahtdh Mar 09 '15 at 05:43
-
1OK, but let's not exaggerate too much. Flex (which does not do DFA minimization) produces a state machine with 89 states and about 2.5k of tables. (It could actually be less than 1k, but flex prefers using int16_t even when it could use uint8_t.) – rici Mar 09 '15 at 06:35
-
@zmo: In DFA, `\d|\d\d|...` and `\d{0,9}` would produce the same number of states. However, depending on implementation of backtracking engine, the resulting states will be less when you write `\d{0,9}`, and there will also be less backtracking. – nhahtdh Mar 09 '15 at 08:12
1
This regex should work:
-\b(?:214748364[0-8]|21474836[0-3][0-9]|2147483[0-5][0-9]{2}|214748[0-2][0-9]{3}|21474[0-7][0-9]{4}|2147[0-3][0-9]{5}|214[0-6][0-9]{6}|21[0-3][0-9]{7}|20[0-9]{8}|1[0-9]{9}|[1-9][0-9]{1,8}|[0-9])\b|\b(?:214748364[0-7]|21474836[0-3][0-9]|2147483[0-5][0-9]{2}|214748[0-2][0-9]{3}|21474[0-7][0-9]{4}|2147[0-3][0-9]{5}|214[0-6][0-9]{6}|21[0-3][0-9]{7}|20[0-9]{8}|1[0-9]{9}|[1-9][0-9]{1,8}|[0-9])\b
Andie2302
- 4,825
- 4
- 24
- 43
-
indeed, it might, but it only helps me to make my point, as the automaton you're generating is just as massive! Just remember that we're talking about converting a string into an int, check if it's within boundaries, which in any language is just as long as going through an array of characters. Just for the fun I'm adding a visualization of your regexp at the end of my answer. N.B.: I'm sure it's better than the one I built. – zmo Mar 09 '15 at 00:11
-
1Why do you include `-0` in `[0-9]|-0)`? Shouldn't `[0-9]` already cover that? – nhahtdh Mar 09 '15 at 05:45
-
1@nhahtdh You are right, the regex also can be written more compact since there are two parts and part one and two differ only in one character. – Andie2302 Mar 09 '15 at 07:56