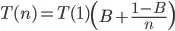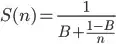Recently a use case came up where I had to kick off several blocking IO tasks at the same time and use them in sequence. I did not want to change the order of operation on the consumption side and since this was a web app and these were short-lived tasks in the request path, I didn't want to bottleneck on a fixed threadpool and was looking to mirror the .Net async/await coding style. The FutureTask<> seemed ideal for this but required an ExecutorService. This is an attempt to remove the need for one.
Order of operation:
- Kick off tasks
- Do some stuff
- Consume Task 1
- Do some other stuff
- Consume Task 2
Finish up
...
I wanted to spawn a new thread for each FutureTask<> but simplify the thread management. After run() completed, the calling thread could be joined.
The solution I came up with was:
package com.staples.search.util;
import java.util.concurrent.Callable;
import java.util.concurrent.Future;
import java.util.concurrent.FutureTask;
public class FutureWrapper<T> extends FutureTask<T> implements Future<T> {
private Thread myThread;
public FutureWrapper(Callable<T> callable) {
super(callable);
myThread = new Thread(this);
myThread.start();
}
@Override
public T get() {
T val = null;
try {
val = super.get();
myThread.join();
}
catch (Exception ex)
{
this.setException(ex);
}
return val;
}
}
Here are a couple of JUnit tests I created to compare FutureWrapper to CachedThreadPool.
@Test
public void testFutureWrapper() throws InterruptedException, ExecutionException {
long startTime = System.currentTimeMillis();
int numThreads = 2000;
List<FutureWrapper<ValueHolder>> taskList = new ArrayList<FutureWrapper<ValueHolder>>();
System.out.printf("FutureWrapper: Creating %d tasks\n", numThreads);
for (int i = 0; i < numThreads; i++) {
taskList.add(new FutureWrapper<ValueHolder>(new Callable<ValueHolder>() {
public ValueHolder call() throws InterruptedException {
int value = 500;
Thread.sleep(value);
return new ValueHolder(value);
}
}));
}
for (int i = 0; i < numThreads; i++)
{
FutureWrapper<ValueHolder> wrapper = taskList.get(i);
ValueHolder v = wrapper.get();
}
System.out.printf("Test took %d ms\n", System.currentTimeMillis() - startTime);
Assert.assertTrue(true);
}
@Test
public void testCachedThreadPool() throws InterruptedException, ExecutionException {
long startTime = System.currentTimeMillis();
int numThreads = 2000;
List<Future<ValueHolder>> taskList = new ArrayList<Future<ValueHolder>>();
ExecutorService esvc = Executors.newCachedThreadPool();
System.out.printf("CachedThreadPool: Creating %d tasks\n", numThreads);
for (int i = 0; i < numThreads; i++) {
taskList.add(esvc.submit(new Callable<ValueHolder>() {
public ValueHolder call() throws InterruptedException {
int value = 500;
Thread.sleep(value);
return new ValueHolder(value);
}
}));
}
for (int i = 0; i < numThreads; i++)
{
Future<ValueHolder> wrapper = taskList.get(i);
ValueHolder v = wrapper.get();
}
System.out.printf("Test took %d ms\n", System.currentTimeMillis() - startTime);
Assert.assertTrue(true);
}
class ValueHolder {
private int value;
public ValueHolder(int val) { value = val; }
public int getValue() { return value; }
public void setValue(int val) { value = val; }
}
Repeated runs puts the FutureWrapper at ~925ms vs. ~935ms for the CachedThreadPool. Both tests bump into OS thread limits.
Things seem to work and the thread spawning is pretty fast (10k threads with random sleeps in ~4s). Does anyone see something wrong with this implementation?