I have tested with sample text both alphanumeric and digits only. I am using digits mode.
How do I recognize digits like in the following image:
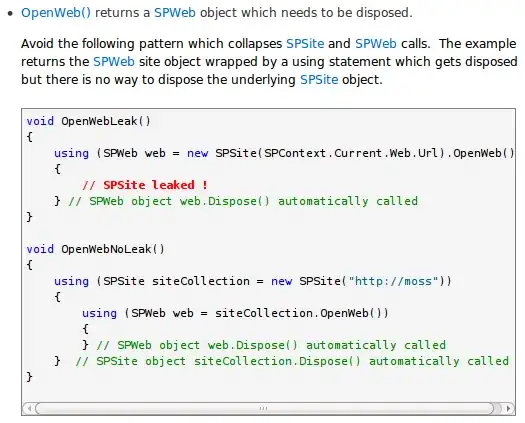
I think it is because of full height. I have also tried converting it to .jpg using some online tools (not code)
I am using pytesseract 0.1.6, but I think this is Tesseract problem.
Here is my code:
def classify(hash):
socket = urllib.urlopen(hash)
image = StringIO(socket.read())
socket.close()
image = Image.open(image)
number = image_to_string(image, config='digits')
mapping[hash] = number
return number
classify('any url')
