can anyone help me with the following regular expression Language of all those words that don’t contain the substring aaaa. i just want to get the idea. i came up with the following R.E
" (ab)*(aaaaa)*"
any help will be appreciated. thanks
can anyone help me with the following regular expression Language of all those words that don’t contain the substring aaaa. i just want to get the idea. i came up with the following R.E
" (ab)*(aaaaa)*"
any help will be appreciated. thanks
You can use a negative look-ahead :
^((?!aaaa).)*$
This will match any combinations of length 0 or more of characters that not followed by aaaa.
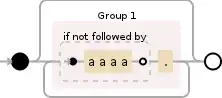
aaaa matches the characters aaaa literally (case sensitive)
. matches any character (except newline)
* Between zero and unlimited times
Also as an alternative and more efficient way in general as @CommuSoft says you can use the following pattern :
^(a{1,3}[^a]|[^a])*a{0,3}$