Updated several times to better describe the current implementation and its usage which was lacking.
What I want to do: I would like to log real time sensor(s) data (voltage) to a log file (CSV) in a size efficient manner (least number of rows). Each row must contain all the sensor data at a specific timestamp. This should allow easy graphing, with X-axis being time.
Currently a new row is added every second with all the sensor data.
A typical problem is that the sensor data does not change for days (similar voltage) but then suddenly changes (large voltage change) every few seconds for a short period of time.
In this case I would like to optimize the log file to only include few points when the data is not changing much, but still capture the period of fast changes.
For example, in the following set of data and I only want a new point when the data changes by more than 10.
+-----------------------------+
| Time(sec) Value1 Value2 |
+-----------------------------+
| 1 0 0 |
| 2 5 3 |
| 3 0 1 |
| ...thousand entries... |
| 1001 15 1 |
| 1002 12 4 |
| 1003 2 1 |
| 1004 3 2 |
| ............... |
+-----------------------------+
Ideally the output would be:
+-----------------------------+
| Time(sec) Value1 Value2 |
+-----------------------------+
| 1 0 0 |
| 1000 5 3 | <<last value? Mean? extrapolation?
| 1001 15 1 |
| 1002 12 4 | <<last value? Mean? extrapolation?
| 1003 2 1 |
| ............... |
+-----------------------------+
The algorithm must handle large sudden value changes with out the resultant looking like a gradual increase, this would happen if in the above example only points 1,1001,1003 where included in the output. It would look like a pyramid rather than a step change!
They are also details such as in the above output example, point 1000, should it be the last point before the step change, or a mean value between all the points from 1-1000?
Ideally an algorithm exist where the optimized output represents the input waveform as accurately as possible.
Current Implementation
Currently all the sensor data is saved once a second to a CSV file. It is then used by non-technical people to view the the trend inside excel or similar by plotting a graph.
The files generated are often very large.
Research
I had a look at Online Linear Regression but I dont think what I want to achieve is curve fitting.
Essentially I dont know what keyword to search for to describe this problem. I have tried the following:
- "how to optimize data captured in a csv file"
- "real time data optimisation by data change algorithm"
- "real time data optimisation by point removal"
Run-length encoding or other encoding pattern compression would no longer allow the user to open the output file for easy graphing. It would first have to be decoded.
"Online Algorithm" Is the name for the general class of algorithms which process input in a serial fashion
Questions:
The resulting CSV file must still be human readable and easily graph-able in excel or similar. This rules out compression or encoding the number of entries in the CSV file.
- Is their a name for this class of problems / algorithm?
- Any commonly used algorithms? (I am programming in C#)
Update 1
An alternative description of what i am looking to happen:
- A new measurement is taken once a second
- The algorithm receives each measurement at a time
- The algorithm output must select/generate the smallest number of points which would represent the original waveform if each point where connected by a line.
- The algorithm must generate this output "online". It does not have the complete dataset.
This description better captures that the output must be a set of points representing the original waveform.
The output must look like the input waveform once graphed in excel or similar. These tools generally just linearly connect the dots.
Here are two example of what the algorithm should be doing. The input data is simplified to be represented with many less points. (Note: Y scales are not identical between examples, the optimization strength would be user controllable)
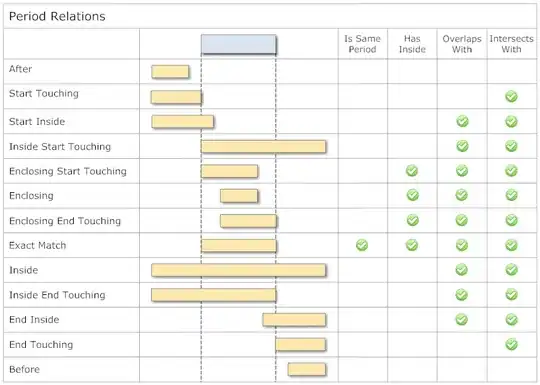
Update 2 Looks like what I am looking may be related to: "Online piecewise linear interpolation"
I have found "piecewise linear interpolation" trying to see if they work for streaming data.
Update 3 "piecewise linear interpolation" is not quite the right algorithm either. This would linearly interpolate between existing points, while i want to generate a new set of points to represent the original data..
Maybe keep monitor the incoming data since the last knot and once all the data can no longer be represented by a line, insert a new knot and restart? Obvious issue is how to optimally choose where to put the knot..
Final Update Added my own answer below. Algorithms called "Line Simplification algorithms" or "downsampling"/ "data compression" algorithms. The "downsampling"/ "data compression" appears better geared to streaming data.
Will most likely use the "Fan" data compression Algorithms for my problem.