I have a table that stores dynamic user data in a key-value pair format. Something like this:
UserId | Key | Value
---------------------------------
1 | gender | male
1 | country | Australia
2 | gender | male
2 | country | US
3 | gender | female
3 | country | Spain
Now, I need to select the users that have certain parameters, for example: gender is 'male' AND country is 'US'. Or more general:
key1=value1 AND key2=value2 AND key3=value3 AND ...
To do so, the fastest way I found is to do the following:
WHERE key=(key1)
AND value=value1
AND EXISTS(SELECT 1
FROM (...)
WHERE key=key2
AND value=value2)
AND EXISTS(SELECT 1
FROM (...)
WHERE key=key3
AND value=value3)
AND EXISTS(...)
In that case, I'll get the best result if the first WHERE filter is for the one whose values are more evenly and segregated.
For example, 'gender' can have 99% males and 1% females and country can partitionate the entire population in 100 similar parts. In that case I would need to filter by country first and use EXIST for the gender condition.
Question: Is there any way in SQL Server 2008 R2 to get the index statistics to find what clause is better to put first (not in the EXISTS basically) ?.
Alternative question: I think that that's the best approach, but a way to rewrite that query to be always optimal can be the solution too.
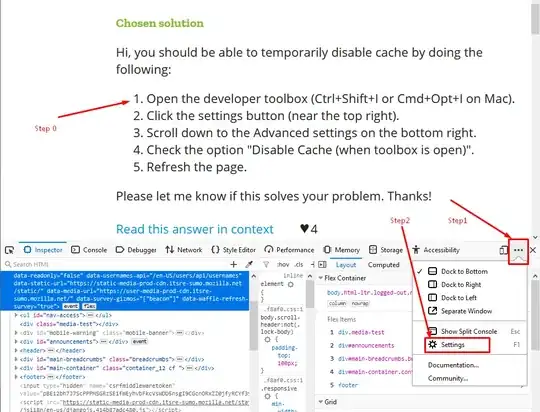
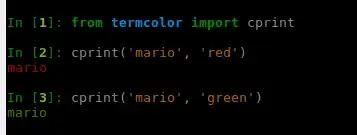
SOLUTION INFORMATION:
The correct solution is the one explained by @usr below (using INTERSECT). Actually it seems I was doing something wrong, the EXISTS was being resolved correctly too by the engine. To provide more info, I am sharing the IO and TIME statistics as well as the execution plan for the options tested:
Using INTERSECT:
Table 'PERFTEST'. Scan count 2, logical reads 113, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 2 ms.
Using EXISTS:
Table 'PERFTEST'. Scan count 2, logical reads 113, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 3 ms.
(Note the extra Stream Aggregate step)
Using INNER JOIN:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'PERFTEST'. Scan count 2, logical reads 113, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 25 ms.

CONCLUSION:
INTERSECT is slightly faster in this case that EXISTS. The INNER JOIN option is way slower.