I would like to highlight some of the key ideas and help you follow along the paper's narrative. This should help you develop some intuition about ARC.
We start with an LRU cache of size c. Other than the cache of pages, we also maintain a cache directory T of size c, which is just an array of metadata describing pages in the cache. Page metadata contains, for example, the physical address of the page in the storage medium.
Now, observe that LRU is not scan-resistant. If a process pulls a sequence of c pages, every page in the cache will be evicted. This is not very efficient, and we want to be able to optimize for both recency and frequency.
Key Idea #1: split the cache into 2 lists: T1 and T2. T1 contains recently used pages, and T2 contains frequently used pages. This is scan-resistant, because a scan will cause T1 to be emptied, but leave T2 mostly unaffected.
When the cache is full, the algorithm has to choose to evict a victim from T1, or from T2. Observe that these lists do not have to have the same size, and we can intelligently give more of the cache to recent pages or frequent pages depending on access patterns. You can invent your own heuristic here.
Key Idea #2: keep extra history. Let B1 and B2 track the metadata of evicted pages from T1 and T2 respectively. If we observe many cache misses in T1 that are hits in B1, we regret the eviction, and give more of the cache to T1.
ARC keeps a number p to split the cache between T1 and T2.
Key Idea #3: On a cache miss in T1 and a hit in B1, ARC increases p by
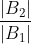 . This is the "delta", or "regret ratio", which compares the probability of a hit in B1 to the probability of a hit in B2, assuming a uniform distribution across all pages.
. This is the "delta", or "regret ratio", which compares the probability of a hit in B1 to the probability of a hit in B2, assuming a uniform distribution across all pages.