I imagine the confusion must be because of the first query.
It does a cartesian join then returns those rows where e.empid != a.empid and then finally applies distinct. These are almost certainly not the semantics you want and they are very different from the second query.
To simplify things lets imagine you have a simple table
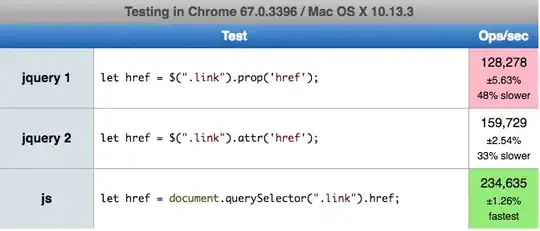
And the query
SELECT DISTINCT e.color
FROM YourTable e
JOIN YourTable AS a
ON e.color != a.color;
First (logical) step is the cartesian join
Then preserve all those rows where e.color != a.color (leaves six rows )

And finally take the DISTINCT of e.color
This is effectively what your first query is doing.
A small amount of thought shows that it will always end up returning all colours from the first table except if the second table is empty and the cross join returns zero rows or the second table just contains a single colour and that is also one of the colours in the first table.
Your second query performs an anti semi join and returns all rows from the left not matched on the right (assuming orderdate is not nullable), other ways of doing it might be using EXCEPT, NOT IN, OUTER APPLY or NOT EXISTS