I've always been under the assumption that not exists is the way to go instead of using a not in condition. However, I doing a comparison on a query I've been using, I noticed that the execution for the Not In condition actually appears to be faster. Any insight into why this could be the case, or if I've just made a horrible assumption up until this point, would be greatly appreciated!
QUERY 1:
SELECT DISTINCT
a.SFAccountID, a.SLXID, a.Name FROM [dbo].[Salesforce_Accounts] a WITH(NOLOCK)
JOIN _SLX_AccountChannel b WITH(NOLOCK)
ON a.SLXID = b.ACCOUNTID
JOIN [dbo].[Salesforce_Contacts] c WITH(NOLOCK)
ON a.SFAccountID = c.SFAccountID
WHERE b.STATUS IN ('Active','Customer', 'Current')
AND c.Primary__C = 0
AND NOT EXISTS
(
SELECT 1 FROM [dbo].[Salesforce_Contacts] c2 WITH(NOLOCK)
WHERE a.SFAccountID = c2.SFAccountID
AND c2.Primary__c = 1
);
QUERY 2:
SELECT
DISTINCT
a.SFAccountID FROM [dbo].[Salesforce_Accounts] a WITH(NOLOCK)
JOIN _SLX_AccountChannel b WITH(NOLOCK)
ON a.SLXID = b.ACCOUNTID
JOIN [dbo].[Salesforce_Contacts] c WITH(NOLOCK)
ON a.SFAccountID = c.SFAccountID
WHERE b.STATUS IN ('Active','Customer', 'Current')
AND c.Primary__C = 0
AND a.SFAccountID NOT IN (SELECT SFAccountID FROM [dbo].[Salesforce_Contacts] WHERE Primary__c = 1 AND SFAccountID IS NOT NULL);
Actual Execution plan for Query 1:

Actual Execution plan for Query 2: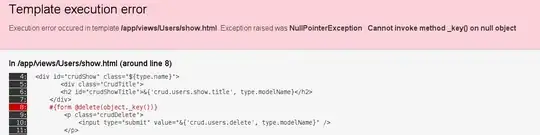
TIME/IO STATISTICS:
Query #1 (using not exists):
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 532 ms, elapsed time = 533 ms.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Salesforce_Contacts'. Scan count 2, logical reads 3078, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'INFORMATION'. Scan count 1, logical reads 691, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'ACCOUNT'. Scan count 4, logical reads 567, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Salesforce_Accounts'. Scan count 1, logical reads 680, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 250 ms, elapsed time = 271 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
Query #2 (using Not In):
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server parse and compile time:
CPU time = 500 ms, elapsed time = 500 ms.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Salesforce_Contacts'. Scan count 2, logical reads 3079, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'INFORMATION'. Scan count 1, logical reads 691, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'ACCOUNT'. Scan count 4, logical reads 567, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Salesforce_Accounts'. Scan count 1, logical reads 680, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 157 ms, elapsed time = 166 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.