Indeed, since C++11, the cost of copying the std::vector is gone in most cases.
However, one should keep in mind that the cost of constructing the new vector (then destructing it) still exists, and using output parameters instead of returning by value is still useful when you desire to reuse the vector's capacity. This is documented as an exception in F.20 of the C++ Core Guidelines.
Let's compare:
std::vector<int> BuildLargeVector1(size_t vecSize) {
return std::vector<int>(vecSize, 1);
}
with:
void BuildLargeVector2(/*out*/ std::vector<int>& v, size_t vecSize) {
v.assign(vecSize, 1);
}
Now, suppose we need to call these methods numIter times in a tight loop, and perform some action. For example, let's compute the sum of all elements.
Using BuildLargeVector1, you would do:
size_t sum1 = 0;
for (int i = 0; i < numIter; ++i) {
std::vector<int> v = BuildLargeVector1(vecSize);
sum1 = std::accumulate(v.begin(), v.end(), sum1);
}
Using BuildLargeVector2, you would do:
size_t sum2 = 0;
std::vector<int> v;
for (int i = 0; i < numIter; ++i) {
BuildLargeVector2(/*out*/ v, vecSize);
sum2 = std::accumulate(v.begin(), v.end(), sum2);
}
In the first example, there are many unnecessary dynamic allocations/deallocations happening, which are prevented in the second example by using an output parameter the old way, reusing already allocated memory. Whether or not this optimization is worth doing depends on the relative cost of the allocation/deallocation compared to the cost of computing/mutating the values.
Benchmark
Let's play with the values of vecSize and numIter. We will keep vecSize*numIter constant so that "in theory", it should take the same time (= there is the same number of assignments and additions, with the exact same values), and the time difference can only come from the cost of allocations, deallocations, and better use of cache.
More specifically, let's use vecSize*numIter = 2^31 = 2147483648, because I have 16GB of RAM and this number ensures that no more than 8GB is allocated (sizeof(int) = 4), ensuring that I am not swapping to disk (all other programs were closed, I had ~15GB available when running the test).
Here is the code:
#include <chrono>
#include <iomanip>
#include <iostream>
#include <numeric>
#include <vector>
class Timer {
using clock = std::chrono::steady_clock;
using seconds = std::chrono::duration<double>;
clock::time_point t_;
public:
void tic() { t_ = clock::now(); }
double toc() const { return seconds(clock::now() - t_).count(); }
};
std::vector<int> BuildLargeVector1(size_t vecSize) {
return std::vector<int>(vecSize, 1);
}
void BuildLargeVector2(/*out*/ std::vector<int>& v, size_t vecSize) {
v.assign(vecSize, 1);
}
int main() {
Timer t;
size_t vecSize = size_t(1) << 31;
size_t numIter = 1;
std::cout << std::setw(10) << "vecSize" << ", "
<< std::setw(10) << "numIter" << ", "
<< std::setw(10) << "time1" << ", "
<< std::setw(10) << "time2" << ", "
<< std::setw(10) << "sum1" << ", "
<< std::setw(10) << "sum2" << "\n";
while (vecSize > 0) {
t.tic();
size_t sum1 = 0;
{
for (int i = 0; i < numIter; ++i) {
std::vector<int> v = BuildLargeVector1(vecSize);
sum1 = std::accumulate(v.begin(), v.end(), sum1);
}
}
double time1 = t.toc();
t.tic();
size_t sum2 = 0;
{
std::vector<int> v;
for (int i = 0; i < numIter; ++i) {
BuildLargeVector2(/*out*/ v, vecSize);
sum2 = std::accumulate(v.begin(), v.end(), sum2);
}
} // deallocate v
double time2 = t.toc();
std::cout << std::setw(10) << vecSize << ", "
<< std::setw(10) << numIter << ", "
<< std::setw(10) << std::fixed << time1 << ", "
<< std::setw(10) << std::fixed << time2 << ", "
<< std::setw(10) << sum1 << ", "
<< std::setw(10) << sum2 << "\n";
vecSize /= 2;
numIter *= 2;
}
return 0;
}
And here is the result:
$ g++ -std=c++11 -O3 main.cpp && ./a.out
vecSize, numIter, time1, time2, sum1, sum2
2147483648, 1, 2.360384, 2.356355, 2147483648, 2147483648
1073741824, 2, 2.365807, 1.732609, 2147483648, 2147483648
536870912, 4, 2.373231, 1.420104, 2147483648, 2147483648
268435456, 8, 2.383480, 1.261789, 2147483648, 2147483648
134217728, 16, 2.395904, 1.179340, 2147483648, 2147483648
67108864, 32, 2.408513, 1.131662, 2147483648, 2147483648
33554432, 64, 2.416114, 1.097719, 2147483648, 2147483648
16777216, 128, 2.431061, 1.060238, 2147483648, 2147483648
8388608, 256, 2.448200, 0.998743, 2147483648, 2147483648
4194304, 512, 0.884540, 0.875196, 2147483648, 2147483648
2097152, 1024, 0.712911, 0.716124, 2147483648, 2147483648
1048576, 2048, 0.552157, 0.603028, 2147483648, 2147483648
524288, 4096, 0.549749, 0.602881, 2147483648, 2147483648
262144, 8192, 0.547767, 0.604248, 2147483648, 2147483648
131072, 16384, 0.537548, 0.603802, 2147483648, 2147483648
65536, 32768, 0.524037, 0.600768, 2147483648, 2147483648
32768, 65536, 0.526727, 0.598521, 2147483648, 2147483648
16384, 131072, 0.515227, 0.599254, 2147483648, 2147483648
8192, 262144, 0.540541, 0.600642, 2147483648, 2147483648
4096, 524288, 0.495638, 0.603396, 2147483648, 2147483648
2048, 1048576, 0.512905, 0.609594, 2147483648, 2147483648
1024, 2097152, 0.548257, 0.622393, 2147483648, 2147483648
512, 4194304, 0.616906, 0.647442, 2147483648, 2147483648
256, 8388608, 0.571628, 0.629563, 2147483648, 2147483648
128, 16777216, 0.846666, 0.657051, 2147483648, 2147483648
64, 33554432, 0.853286, 0.724897, 2147483648, 2147483648
32, 67108864, 1.232520, 0.851337, 2147483648, 2147483648
16, 134217728, 1.982755, 1.079628, 2147483648, 2147483648
8, 268435456, 3.483588, 1.673199, 2147483648, 2147483648
4, 536870912, 5.724022, 2.150334, 2147483648, 2147483648
2, 1073741824, 10.285453, 3.583777, 2147483648, 2147483648
1, 2147483648, 20.552860, 6.214054, 2147483648, 2147483648
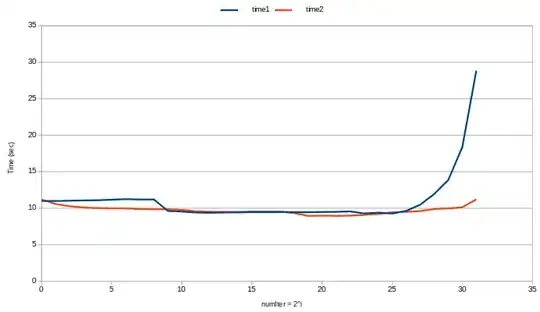
(Intel i7-7700K @ 4.20GHz; 16GB DDR4 2400Mhz; Kubuntu 18.04)
Notation: mem(v) = v.size() * sizeof(int) = v.size() * 4 on my platform.
Not surprisingly, when numIter = 1 (i.e., mem(v) = 8GB), the times are perfectly identical. Indeed, in both cases we are only allocating once a huge vector of 8GB in memory. This also proves that no copy happened when using BuildLargeVector1(): I wouldn't have enough RAM to do the copy!
When numIter = 2, reusing the vector capacity instead of re-allocating a second vector is 1.37x faster.
When numIter = 256, reusing the vector capacity (instead of allocating/deallocating a vector over and over again 256 times...) is 2.45x faster :)
We can notice that time1 is pretty much constant from numIter = 1 to numIter = 256, which means that allocating one huge vector of 8GB is pretty much as costly as allocating 256 vectors of 32MB. However, allocating one huge vector of 8GB is definitly more expensive than allocating one vector of 32MB, so reusing the vector's capacity provides performance gains.
From numIter = 512 (mem(v) = 16MB) to numIter = 8M (mem(v) = 1kB) is the sweet spot: both methods are exactly as fast, and faster than all other combinations of numIter and vecSize. This probably has to do with the fact that the L3 cache size of my processor is 8MB, so that the vector pretty much fits completely in cache. I don't really explain why the sudden jump of time1 is for mem(v) = 16MB, it would seem more logical to happen just after, when mem(v) = 8MB. Note that surprisingly, in this sweet spot, not re-using capacity is in fact slightly faster! I don't really explain this.
When numIter > 8M things start to get ugly. Both methods get slower but returning the vector by value gets even slower. In the worst case, with a vector containing only one single int, reusing capacity instead of returning by value is 3.3x faster. Presumably, this is due to the fixed costs of malloc() which start to dominate.
Note how the curve for time2 is smoother than the curve for time1: not only re-using vector capacity is generally faster, but perhaps more importantly, it is more predictable.
Also note that in the sweet spot, we were able to perform 2 billion additions of 64bit integers in ~0.5s, which is quite optimal on a 4.2Ghz 64bit processor. We could do better by parallelizing the computation in order to use all 8 cores (the test above only uses one core at a time, which I have verified by re-running the test while monitoring CPU usage). The best performance is achieved when mem(v) = 16kB, which is the order of magnitude of L1 cache (L1 data cache for the i7-7700K is 4x32kB).
Of course, the differences become less and less relevant the more computation you actually have to do on the data. Below are the results if we replace sum = std::accumulate(v.begin(), v.end(), sum); by for (int k : v) sum += std::sqrt(2.0*k);:
Conclusions
- Using output parameters instead of returning by value may provide performance gains by re-using capacity.
- On a modern desktop computer, this seems only applicable to large vectors (>16MB) and small vectors (<1kB).
- Avoid allocating millions/billions of small vectors (< 1kB). If possible, re-use capacity, or better yet, design your architecture differently.
Results may differ on other platforms. As usual, if performance matters, write benchmarks for your specific use case.

