Well, as usual, using a regex to match an URL is the wrong tool for the wrong job. You can use urlparse (or urllib.parse in python3) to do the job, in a very pythonic way:
>>> from urlparse import urlparse
>>> urlparse('http://www.example.es/cat1/cat2/some-example_DH148439#.Rh1-js_4')
ParseResult(scheme='http', netloc='www.example.es', path='/cat1/cat2/some-example_DH148439', params='', query='', fragment='.Rh1-js_4')
>>> urlparse('http://www.example.es/cat1/cat2/cat3')
ParseResult(scheme='http', netloc='www.example.es', path='/cat1/cat2/cat3', params='', query='', fragment='')
and if you really want a regex, the following regex is an example that would answer your question:
import re
>>> re.match(r'^[^:]+://([^.]+\.)+[^/]+/([^/]+/)+[^#]+(#.+)?$', 'http://www.example.es/cat1/cat2/some-example_DH148439#.Rh1-js_4') != None
True
>>> re.match(r'^[^:]+://([^.]+\.)+[^/]+/([^/]+/)+[^#]+(#.+)?$', 'http://www.example.es/cat1/cat2/cat3') != None
True
but the regex I'm giving is good enough to answer your question, but is not a good way to validate an URL, or to split it in pieces. I'd say its only interest is to actually answer your question.
Here's the automaton generated by the regex, to better understand it:

Beware of what you're asking, because JL's regex won't match:
http://www.example.es/cat1/cat2/cat3
as after rereading your question 3×, you're actually asking for the following regex:
\/([^/]*)$
which will match both your examples:
http://www.example.es/cat1/cat2/some-example_DH148439#.Rh1-js_4
http://www.example.es/cat1/cat2/cat3
What @jl-peyret suggests, is only how to match a litteral dot following a /, which is generating the following automaton:
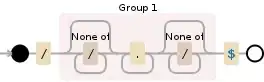
So, whatever you really want:
- use urlparse whenever you can to match parts of an URL
- if you're trying to define a django route, then trying to match the fragment is hopeless
- next time you do a question, please make it precise, and give an example of what you tried: help us help you.