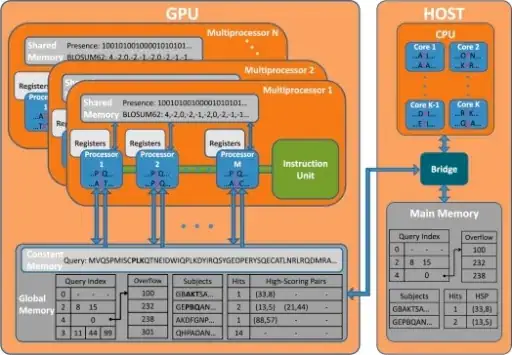
I am trying to understand the basic architecture of a GPU. I have gone through a lot of material including this very good SO answer. But I am still confused not able to get a good picture of it.
My Understanding:
- A GPU contains two or more Streaming Multiprocessors (SM) depending upon the compute capablity value.
- Each SM consists of Streaming Processors (SP) which are actually responisible for the execution of instructions.
- Each block is processed by SP in form of warps (32 threads).
- Each block has access to a shared memory. A different block cannot access the data of some other block's shared memory.
Confusion:
In the following image, I am not able to understand which one is the Streaming Multiprocessor (SM) and which one is SP. I think that Multiprocessor-1 respresent a single SM and Processor-1 (upto M) respresent a single SP. But I am not sure about this because I can see that each Processor (in blue color) has been provided a Register but as far as I know, a register is provided to a thread unit.
It would be very helpful to me if you could provide some basic overview w.r.t this image or any other image.