if there are several links it only replaces the last one
Where is my error?
Actually, it's replacing all 3 links, but it replaces the original string each time.
foreach($matches[0] AS $match)
{
$html_url = '<a href="' . $match . '" target="_blank">' . $match . '</a>';
$match_string = str_replace($match, $html_url, $match_code);
}
The loop is executed 3 times, each time it replaces 1 link in $match_code and assigns the result to $match_string. On the first iteration, $match_string is assigned the result with a clickable google.com. On the second iteration, $match_string is assigned with a clickable yahoo.com. However, you've just replaced the original string, so google.com is not clickable now. That's why you only get your last link as a result.
There are a couple of things you may also want to correct in your code:
- The regex
#<pre[\s\S]*</pre>#U is better constructed as #<pre.*</pre>#Us. The class [\s\S]* is normally used in JavaScript, where there is no s flag to allow dots matching newlines.
- I don't get why you're using that pattern to match URLs. I think you could simply use
https?://\S+. I'll also link you to some alternatives here.
- You're using 2
preg_match_all() calls and 1 str_replace() call for the same text, where you could wrap it up in 1 preg_replace().
Code
$postbits = "
<pre>
http://www.google.com
http://w...content-available-to-author-only...o.com
http://www.microsoft.com/ <-- only this one clickable
</pre>";
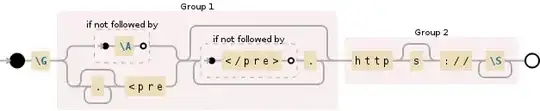
$regex = '#\G((?:(?!\A)|.*<pre)(?:(?!</pre>).)*)(https?://\S+?)#isU';
$repl = '\1<a href="\2" target="_blank">\2</a>';
$postbits = preg_replace( $regex, $repl, $postbits);
ideone demo
Regex
\G Always from the first matching position in the subject.- Group 1
(?:(?!\A)|.*<pre) Matches the first <pre tag from the beggining of the string, or allows to get the next <pre tag if no more URLs found in this tag.(?:(?!</pre>).)*) Consumes any chars inside a <pre> tag.
- Group 2
(https?://\S+?) Matches 1 URL.