I am wondering about the best way for generating mysql reports in large databases, as I have a database for POS application with more than 40 stores working on it.
The database has more that 1.5M rows for each of four tables. two for headers and other for details.
I am generating reports by joining headers with details and some other tables to get full info for the view.
I tried to archive the data in one table, which has all data required for reporting, but I found it's a huge load, and MySQL events for fetching data to that table not always working, and may lead to data loss.
I've also tried indexing tables, but didn't help too much as the queries are too big and take too much time, which lead to heavy load on the server and may stop the application with not responding at all.
I searched across google, and found some ideas about partitioning tables, and others about archiving, changing the whole engine or even upgrading server requirements.
The relation between two tables (invoice_header and invoice_detail) is (one to many) that the invoice_header is the header of an invoice, with only totals. Which is linked to invoice_detail using location ID (loc_id) and Invoice number (invo_no), as each location has its own serial number. The invoice detail contains the details of each invoice.
Sample Query:
The query takes too long (15 - 20) seconds to fetch
-Total rows: 1495873
-Total Fetched rows: 9 - 12
SELECT SUM(invoice_detail.qty) AS qty, Month(invoice_header.date) AS month
FROM invoice_detail
JOIN invoice_header ON invoice_detail.invo_no = invoice_header.invo_no
AND invoice_detail.loc_id = invoice_header.loc_id
WHERE invoice_detail.item_id = {$itemId}
GROUP BY Month(invoice_header.date)
ORDER BY Month(invoice_header.date)
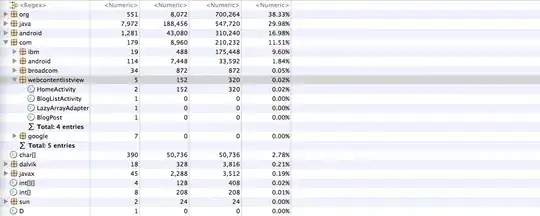
EXPLAIN:
invoice_header table structure:
CREATE TABLE `invoice_header` (
`invo_type` varchar(1) NOT NULL,
`invo_no` int(20) NOT NULL AUTO_INCREMENT,
`invo_code` varchar(50) NOT NULL,
`date` date NOT NULL,
`time` time NOT NULL,
`cust_id` int(11) NOT NULL,
`loc_id` int(3) NOT NULL,
`cash_man_id` int(11) NOT NULL,
`sales_man_id` int(11) NOT NULL,
`ref_invo_no` int(20) NOT NULL,
`total_amount` decimal(19,2) NOT NULL,
`tax` decimal(19,2) NOT NULL,
`discount_amount` decimal(19,2) NOT NULL,
`net_value` decimal(19,2) NOT NULL,
`split` decimal(19,2) NOT NULL,
`qty` int(11) NOT NULL,
`payment_type_id` varchar(20) NOT NULL,
`comments` varchar(255) NOT NULL,
PRIMARY KEY (`invo_no`,`loc_id`)
) ENGINE=InnoDB AUTO_INCREMENT=20286 DEFAULT CHARSET=utf8
invoice_detail table structure:
CREATE TABLE `invoice_detail` (
`invo_no` int(11) NOT NULL,
`loc_id` int(3) NOT NULL,
`serial` int(11) NOT NULL,
`item_id` varchar(11) NOT NULL,
`size_id` int(5) NOT NULL,
`qty` int(11) NOT NULL,
`rtp` decimal(19,2) NOT NULL,
`type` tinyint(1) NOT NULL,
PRIMARY KEY (`invo_no`,`loc_id`,`serial`),
KEY `item_id` (`item_id`),
KEY `size_id` (`size_id`),
KEY `invo_no` (`invo_no`),
KEY `serial` (`serial`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
After adding "Extract":
EXPLAIN SELECT SUM( invoice_detail.qty ) AS qty, Month( invoice_header.date ) AS
MONTH
FROM invoice_detail
JOIN invoice_header ON invoice_detail.invo_no = invoice_header.invo_no
AND invoice_detail.loc_id = invoice_header.loc_id
WHERE invoice_detail.item_id =11321
GROUP BY EXTRACT(
YEAR_MONTH FROM invoice_header.date )

I am using a quite good dedicated server with:
Intel Xeon Quad Core 3.3GHz (8 threads)
1 Gbps Uplink
16 GB RAM
1,000 GB RAID-1 Drives
25 TB Bandwidth
Any suggestions?