I am trying to apply a function to each row in a dataframe. The problem is, the function requires output from the previous row as an input.
def emaIrregular(alpha, sample, sampleprime, deltats, emaprime):
a = deltats / float(alpha)
u = math.exp(a * -1)
v = (1 - u) / a
return (u * emaprime) + ((v - u) * prevprime) +((1.0 - v) * sample)
The issue is from the parameter emaprime as this is computing the current ema value. I am aware I can shift the df to get sampleprime and deltats values.
The function I am using is slightly complex: here is a toy example I hope will help.
def myRollingSum(x, xprime):
return x + xprime
So the similar to a rollingsum as it uses the output from the previous iteration as the input for the next.
Edit
Ok, myRollingSum example is throwing people off. I need to access the result of the previous row, but this result is the thing being computed! i.e. 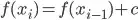 . Alternatively, similar to the way a factorial is commutated.
. Alternatively, similar to the way a factorial is commutated.
My data is sparse and irregularly spaced. It is not feasible to resample/interpolate and run over this expanded dataset for each window.
I have a feeling there is not an easy way to do this, apart from iterating over each record one by one?