It seems like you've known at least one other language before powershell, and are starting out by basically replicating what you might have done in another language in this one. That's a great way to learn a new language, but of course in the beginning you might end up with methods that are a bit strange or not performant.
So first I want to break down what your code is actually doing, as a rough overview:
- Read every line of the file at once and store it in the
$Dict variable.
- Loop the same number of times as there are lines.
- In each iteration of the loop:
- Get the single line that matches the loop iteration (essentially through another iteration, rather than indexing, more on that later).
- Get the first character of the line, then the second, then combine them.
- If that's equal to a pre-determined string, append this line to a text file.
Step 3-1 is what's really slowing this down
To understand why, you need to know a little bit about pipelines in PowerShell. Cmdlets that accept and work on pipelines take one or more objects, but they process a single object at a time. They don't even have access to the rest of the pipeline.
This is also true for the Select-Object cmdlet. So when you take an array with 18,500 objects in it, and pipe it into Select-Object -Index 18000, you need to send in 17,999 objects for inspection/processing before it can give you the one you want. You can see how the time taken would get longer and longer the larger the index is.
Since you already have an array, you directly access any array member by index with square brackets [] like so:
$Dict[18000]
For a given array, that takes the same amount of time no matter what the index is.
Now for a single call to Select-Object -Index you probably aren't going to notice how long it takes, even with a very large index; the problem is that you're looping through the entire array already, so this is compounding greatly.
You're essentially having to do the sum of 1..18000 which is about 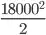 or approximately 162,000,000 iterations! (thanks to user2460798 for correcting my math)
or approximately 162,000,000 iterations! (thanks to user2460798 for correcting my math)
Proof
I tested this. First, I created an array with 19,000 objects:
$a = 1..19000 | %{"zzzz~$_"}
Then I measured both methods of accessing it. First, with select -index:
measure-command { 1..19000 | % { $a | select -Index ($_-1 ) } | out-null }
Result:
TotalMinutes : 20.4383861316667
TotalMilliseconds : 1226303.1679
Then with the indexing operator ([]):
measure-command { 1..19000 | % { $a[$_-1] } | out-null }
Result:
TotalMinutes : 0.00788774666666667
TotalMilliseconds : 473.2648
The results are pretty striking, it takes nearly 2,600 times longer to use Select-Object.
A counting loop
The above is the single thing causing your major slowdown, but I wanted to point out something else.
Typically in most languages, you would use a for loop to count. In PowerShell this would look like this:
for ($i = 0; $i -lt $total ; $i++) {
# $i has the value of the iteration
}
In short, there are three statements in the for loop. The first is an expression that gets run before the loop starts. $i = 0 initializes the iterator to 0, which is the typical usage of this first statement.
Next is a conditional; this will be tested on each iteration and the loop will continue if it returns true. Here $i -lt $total compares checks to see that $i is less than the value of $total, some other variable defined elsewhere, presumably the maximum value.
The last statement gets executed on each iteration of the loop. $i++ is the same as $i = $i + 1 so in this case we're incrementing $i on each iteration.
It's a bit more concise than using a do/until loop, and it's easier to follow because the meaning of a for loop is well known.
Other Notes
If you're interested in more feedback about working code you've written, have a look at Code Review. Please read the rules there carefully before posting.