It often helps to visualize the regular expression:

Note that (?:.){0,}? is a roundabout way of saying .*. It's also easy to see now that there's two identical blocks which could merged, so lets fix that:
label\W+(?:(?:\w+\W+){1,60}?.*(\<TAG1\>|\<TAG2\>).*){2}
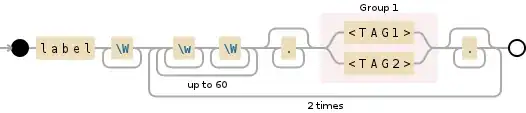
This is equivalent, but shorter. From here it becomes a question of what exactly you're trying to match. All those \ws an \Ws look a little odd to me, especially when used alongside .'s. I generally prefer to match \s rather than \W since I usually really do mean "some sort of whitespace", but you'll need to decide which you actually need.
The "match-one-to-sixty-words-and-not-words-followed-by-anything" pattern you're using ((?:\w+\W+){1,60}?.*) is likely not what you want - it would match a$<TAG for instance, but not a<TAG. If you want to allow one or more words try (?:\s*\w+)+. This matches zero-or-more whitespace, followed by one-or-more characters, one or more times. If you want to limit that to 60 you can replace the final + with a {1,60} (but it's not clear from your description where the 60 comes from - do you need it?).
So here's where we are now:
label\s+(?:(?:\w+\s*)+(\<TAG1\>|\<TAG2\>)\w*){2}
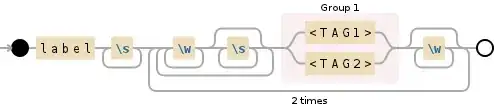
This isn't quite identical to your previous pattern - it doesn't match after in your example string (it's not clear from you description whether it should or not). If you want to keep matching after the second tag, just add a .* to the end.
All that said, it looks a lot like you're trying to parse a complex grammar (i.e. a non-regular language), and that is rife with peril. If you find yourself writing and rewriting a regular expression to try to make it capture the data you need, you may need to upgrade to a proper contextual parser.
In particular, neither your regular expression nor my tweaks enforce that N is the same each time. Your description makes it sound like you only want to match strings where there are N words preceeding the first tag, and exactly N words in-between it and the second tag. That sort of match might be possible with regular expressions, but it certainly wouldn't be clean. If that's a requirement, regular expressions likely aren't the right tool.