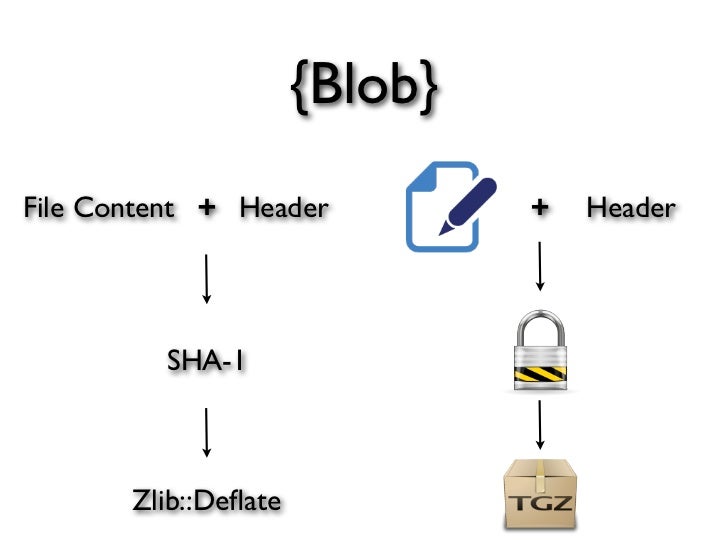
I'm wondering about what git is doing when it pushes up changes, and why it seems to occasionally push way more data than the changes I've made. I made some changes to two files that added around 100 lines of code - less than 2k of text, I'd imagine.
When I went to push that data up to origin, git turned that into over 47mb of data:
git push -u origin foo
Counting objects: 9195, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (6624/6624), done.
Writing objects: 100% (9195/9195), 47.08 MiB | 1.15 MiB/s, done.
Total 9195 (delta 5411), reused 6059 (delta 2357)
remote: Analyzing objects... (9195/9195) (50599 ms)
remote: Storing packfile... done (5560 ms)
remote: Storing index... done (15597 ms)
To <<redacted>>
* [new branch] foo -> foo
Branch foo set up to track remote branch foo from origin.
When I diff my changes, (origin/master..HEAD) only the two files and one commit I did show up. Where did the 47mb of data come from?
I saw this: When I do "git push", what do the statistics mean? (Total, delta, etc.) and this: Predict how much data will be pushed in a git push but that didn't really tell me what's going on... Why would the pack / bundle be huge?