I've written a SQL query that uses six tables to construct the output for a separate C# program, and I'm looking for a way to speed up the search.
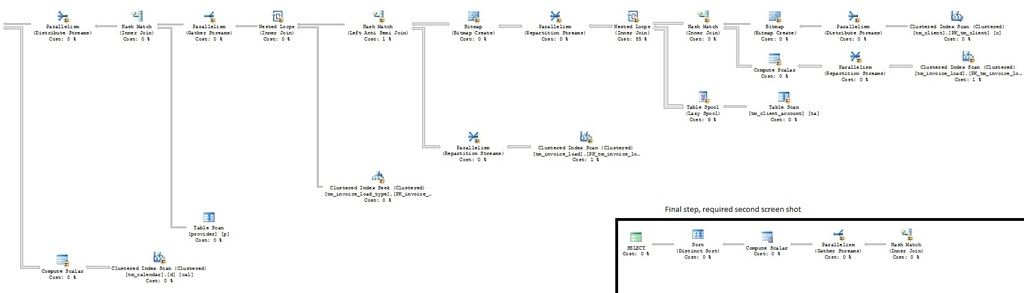
I walked through the execution plan and I notice that one spot in particular is taking up 85% of the execution time, labeled with a comment in the code block below with --This spot right here.
select distinct
ta.account_num as 'Account',
tl.billing_year as 'Year',
tl.billing_month as 'Month',
ta.bill_date as 'Bill Date',
DATEDIFF(DD, cast(cast(tl.billing_year as varchar(4)) + right('0' + cast(tl.billing_month as varchar(2)), 2) + right('0' + (case when billing_month in (4,6,9,11) and bill_date > 30 then '30' when billing_month = 2 and bill_date > 28 then '28' else cast(bill_date as varchar(2)) end), 2) as datetime), GETDATE()) as 'Past',
DATEADD(Day,10,d) as 'To be Loaded Before',
p.provider_name as 'Provider',
c.client as 'Client',
tip.invoice_load_type as 'Load Type'
from
tm_invoice_load tl
inner join
tm_client c on tl.client_id = c.client_id
inner join
tm_client_account ta on (ta.account_num = tl.account_num or ta.pilot = tl.account_num) --This spot right here
inner join
provider p on p.id_provider = ta.id_provider
inner join
tm_calendar cal on DATEPART(DAY, d) = DATEPART(DAY, entry_dt)
and DATEPART(MONTH, d) = DATEPART(MONTH, entry_dt)
and DATEPART(YEAR, d) = DATEPART(YEAR, entry_dt)
inner join
tm_invoice_load_type tip on tip.invoice_load_type_id = ta.invoice_load_type_id
where
not exists (select top 1 id
from tm_invoice_load
where billing_year = tl.billing_year
and billing_month = tl.billing_month
and status_id = 1
and (account_num = ta.account_num or account_num = ta.pilot))
and ta.status_id = 1
--and ta.invoice_load_type_id = 2
and tl.status_id = 2
and (ta.pilot is null or ta.account_num <> ta.pilot)
order by
c.client, p.provider_name, ta.account_num, tl.billing_year, tl.billing_month
Above, it's when joining tm_client_account, where it has an account number column, and a pilot in case it is a child to another account. When such a thing happens, the parent account is NOT selected (ta.pilot is null or ta.account_num <> ta.pilot), and instead the child accounts are shown.
The query works exactly as intended, but it's kinda slow, and as these tables grow (and they are doing so on a nearly exponential curve) it will only get worse.
Is there some way that I can accomplish this join in a faster way? Even small gains would be great!
If it helps, I'm running this on SQL Server 2008 R2.
Here is a screenshot of the execution plan. If needed, I can provide more/different information.
{kind=link}