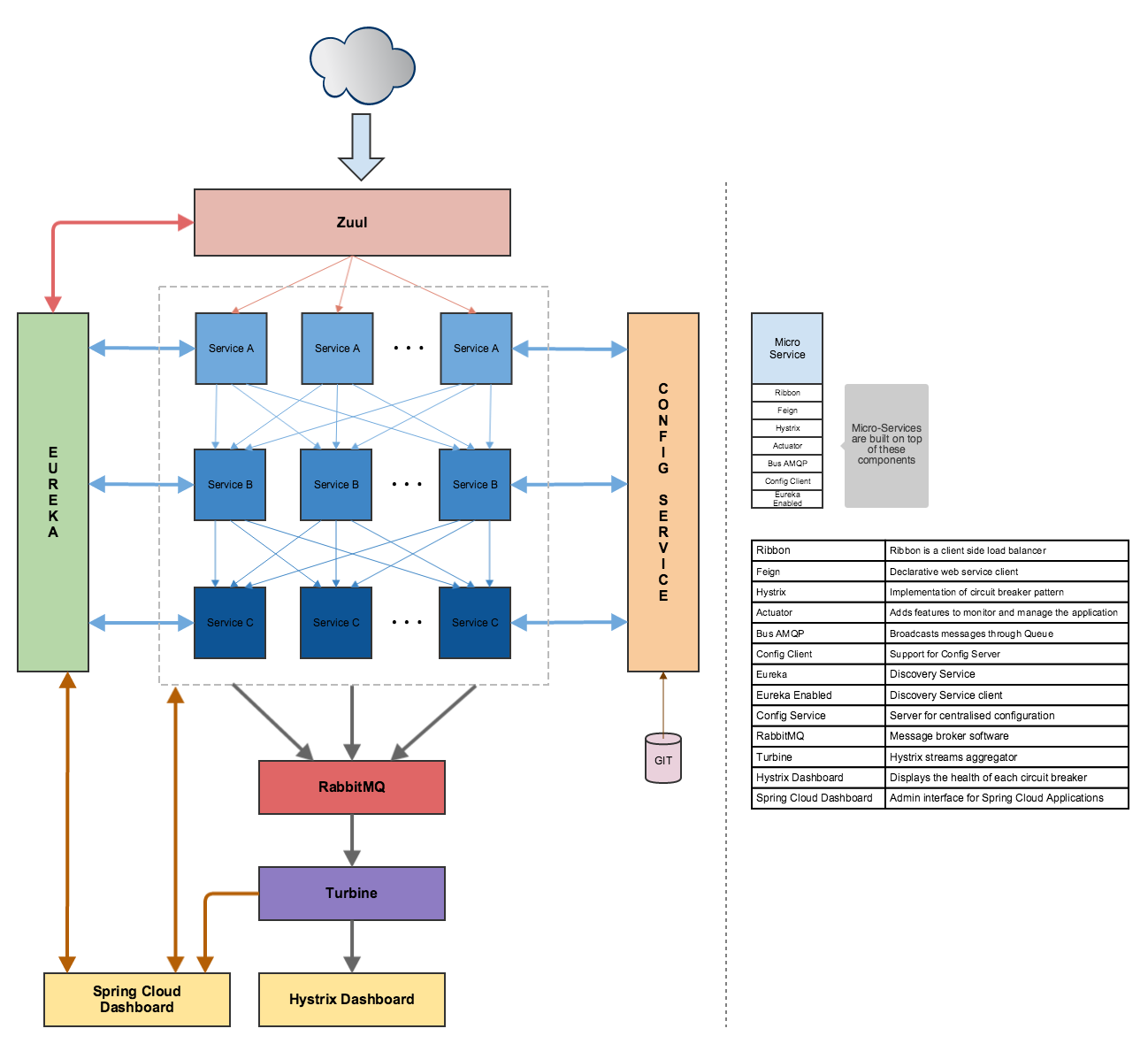
I'm experimenting with a setup that is very much like the one detailed in the image here: https://raw.githubusercontent.com/Oreste-Luci/netflix-oss-example/master/netflix-oss-example.png
{kind=link}
In my setup, I'm using a client application (https://www.joedog.org/siege-home/), a proxy (Zuul), a discovery service (Eureka) and a simple microservice. Everything is deployed on PWS.
I want to migrate from one version of my simple microservice to the next without any downtime. Initially I started out with the technique described here: https://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
In my opinion, this approach is not "compatible" with a discovery service such as Eureka. In fact, the new version of my service is registered in Eureka and receives traffic even before I can remap all the routes (CF Router).
This lead me to another approach, in which I rely on the failover mechanisms in Spring Cloud/Netflix:
- I spin up a new (backwards compatible) version of my service.
- When this version is picked up by Zuul/Eureka it starts getting 50% of the traffic.
- Once I verified that the new version works correctly I take down the "old" instance. (I just click the "stop" button in PWS)
As I understand, Zuul uses Ribbon (load-balancing) under the hood so in that split second where the old instance is still in Eureka but actually shutting down, I expect a retry on the new instance without any impact on the client.
However, my assumption is wrong. I get a few 502 errors in my client:
Lifting the server siege... done.
Transactions: 5305 hits
Availability: 99.96 %
Elapsed time: 59.61 secs
Data transferred: 26.06 MB
Response time: 0.17 secs
Transaction rate: 89.00 trans/sec
Throughput: 0.44 MB/sec
Concurrency: 14.96
Successful transactions: 5305
Failed transactions: 2
Longest transaction: 3.17
Shortest transaction: 0.14
Part of my application.yml
server:
port: ${PORT:8765}
info:
component: proxy
ribbon:
MaxAutoRetries: 2 # Max number of retries on the same server (excluding the first try)
MaxAutoRetriesNextServer: 2 # Max number of next servers to retry (excluding the first server)
OkToRetryOnAllOperations: true # Whether all operations can be retried for this client
ServerListRefreshInterval: 2000 # Interval to refresh the server list from the source
ConnectTimeout: 3000 # Connect timeout used by Apache HttpClient
ReadTimeout: 3000 # Read timeout used by Apache HttpClient
hystrix:
threadpool:
default:
coreSize: 50
maxQueueSize: 100
queueSizeRejectionThreshold: 50
command:
default:
execution:
isolation:
thread:
timeoutInMilliseconds: 10000
I'm not sure what goes wrong.
Is this a technical issue?
Or am I making the wrong assumptions (I did read somewhere that POSTs are not retried anyway, which I don't really understand)?
I'd love to hear how you do it.
Thanks, Andy