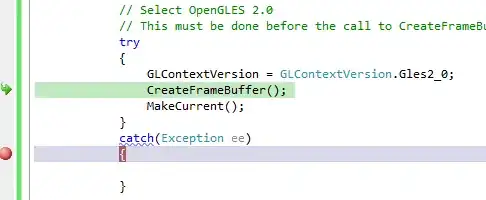
Just like in the case of the question the OP references (Removing Watermark from PDF iTextSharp), you can remove the watermark from your sample file by building upon the PdfContentStreamEditor class presented in my answer to that question.
In contrast to the solution in that other answer, though, we do not want to hide vector graphics based on some transparency value but instead the writing "Archive of SID" from this:
First we have to select a criterion to recognize the background text by. Let's use the fact that the writing is by far the largest here. Using this criterion makes the task at hand essentially the iTextSharp/C# pendant to this iText/Java solution.
There is a problem, though: As mentioned in that answer:
The gs().getFontSize() used in the second sample may not be what you expect it to be as sometimes the coordinate system has been stretched by the current transformation matrix and the text matrix. The code can be extended to consider these effects.
Exactly this is happening here: A font size of 1 is used and that small text then is stretched by means of the text matrix:
/NxF0 1 Tf
49.516754 49.477234 -49.477234 49.516754 176.690933 217.316086 Tm
Thus, we need to take the text matrix into account. Unfortunately the text matrix is a private member. Thus, we will also need some reflection magic.
Thus, a possible background remover for that file looks like this:
class BigTextRemover : PdfContentStreamEditor
{
protected override void Write(PdfContentStreamProcessor processor, PdfLiteral operatorLit, List<PdfObject> operands)
{
if (TEXT_SHOWING_OPERATORS.Contains(operatorLit.ToString()))
{
Vector fontSizeVector = new Vector(0, Gs().FontSize, 0);
Matrix textMatrix = (Matrix) textMatrixField.GetValue(this);
Matrix curentTransformationMatrix = Gs().GetCtm();
Vector transformedVector = fontSizeVector.Cross(textMatrix).Cross(curentTransformationMatrix);
float transformedFontSize = transformedVector.Length;
if (transformedFontSize > 40)
return;
}
base.Write(processor, operatorLit, operands);
}
System.Reflection.FieldInfo textMatrixField = typeof(PdfContentStreamProcessor).GetField("textMatrix", System.Reflection.BindingFlags.NonPublic | System.Reflection.BindingFlags.Instance);
List<string> TEXT_SHOWING_OPERATORS = new List<string>{"Tj", "'", "\"", "TJ"};
}
The 40 has been chosen with that text matrix in mind.
Applying it like this
[Test]
public void testRemoveBigText()
{
string source = @"sid-1.pdf";
string dest = @"sid-1-noBigText.pdf";
using (PdfReader pdfReader = new PdfReader(source))
using (PdfStamper pdfStamper = new PdfStamper(pdfReader, new FileStream(dest, FileMode.Create, FileAccess.Write)))
{
PdfContentStreamEditor editor = new BigTextRemover();
for (int i = 1; i <= pdfReader.NumberOfPages; i++)
{
editor.EditPage(pdfStamper, i);
}
}
}
to your sample file results in: