I want to create a proper preg_match pattern to extract all <link *rel="stylesheet"* /> within the <head> of some webpages. So this pattern: #<link (.+?)>#is worked fine until I realized it catches also the <link rel="shortcut icon" href="favicon.ico" /> that's in the <head>. So I want to alter the pattern so that it makes sure there IS the word stylesheet somewhere WITHIN the link. I think it needs to use some lookaround but I'm not sure how to do it. Any help will be much appreciated.
Asked
Active
Viewed 196 times
0
-
2You should look into using a parser. – chris85 May 21 '16 at 14:58
-
You mean like extracting all including the favicon ones and then excluding them? The problem is there are some counters in the code that already count the favicon tags so it meshes with my calculations. Isn't really a way to properly do it within the initial preg_match_all pattern? – Peter K. May 21 '16 at 15:03
-
Eg. This seems to get the job done but the explanation generated from the pattern on regex101.com didn't convince me it's properly done. This is the explanation it gives me: 1st Capturing group ([stylesheet].+?) [stylesheet] match a single character present in the list below stylesheet a single character in the list styleh literally (case insensitive) .+? matches any character Quantifier: +? Between one and unlimited times, as few times as possible, expanding as needed [lazy] – Peter K. May 21 '16 at 15:09
-
1`[stylesheet]` is a character class allowing one of those characters, you dont want that. You could use an xpath with a parser to pull this. Alternatively you could use ``. A parser would be a lot more reliable though. – chris85 May 21 '16 at 15:12
-
@chris85 Yup, this was exactly what I was looking for. Thanks a lot mate! – Peter K. May 21 '16 at 15:19
2 Answers
2
Here we go again... don't use a regex to parse html, use an html parser like PHP DOMDocument.
Here's an example of how to use it:
$html = file_get_contents("https://stackoverflow.com");
$dom = new DOMDocument();
libxml_use_internal_errors(true);
$dom->loadHTML($html);
$xpath = new DOMXpath($dom);
foreach ($xpath->query("//link[@rel='stylesheet']") as $link)
{
echo $link->getAttribute("href");
}
Community
- 1
- 1
Pedro Lobito
- 94,083
- 31
- 258
- 268
0
To do this with regular expressions, it would be best to do this as a two part operation, the first part is to separate out the head from the body to ensure you're only working within the head.
Then second part will parse the head looking for the desired links
Parsing Links
<link\s*(?=(?:[^>=]|='[^']*'|="[^"]*"|=[^'"][^\s>]*)*?rel=['"]?stylesheet)(?:[^>=]|='(?:[^']|\\')*'|="(?:[^"]|\\")*"|=[^'"][^\s>]*)*\s*>
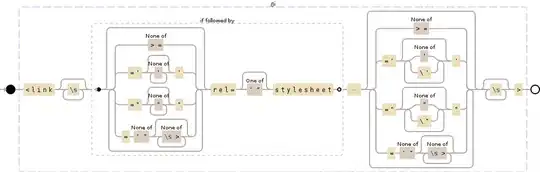
This expression will do the following:
- find all the
<linktags - ensure the link tag has the desired attribute
rel='stylesheet - allow attribute values to have single, double or no quotes
- avoid messy and difficult edge cases that the HTML Parse Police cry about
Example
Live Demo
https://regex101.com/r/hC5dD0/1
Sample Text
Note the difficult edge case in the last line.
<link *rel="stylesheet"* />
<link rel="shortcut icon" href="favicon.ico" />
<link onmouseover=' rel="stylesheet" ' rel="shortcut icon" href="favicon.ico">
Sample Matches
<link *rel="stylesheet"* />
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
<link '<link'
----------------------------------------------------------------------
\s* whitespace (\n, \r, \t, \f, and " ") (0 or
more times (matching the most amount
possible))
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the least amount
possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)*? end of grouping
----------------------------------------------------------------------
rel= 'rel='
----------------------------------------------------------------------
['"]? any character of: ''', '"' (optional
(matching the most amount possible))
----------------------------------------------------------------------
stylesheet 'stylesheet'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture (0 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
[^'] any character except: '''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\\ '\'
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
[^"] any character except: '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\\ '\'
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"] any character except: ''', '"'
----------------------------------------------------------------------
[^\s>]* any character except: whitespace (\n,
\r, \t, \f, and " "), '>' (0 or more
times (matching the most amount
possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
\s* whitespace (\n, \r, \t, \f, and " ") (0 or
more times (matching the most amount
possible))
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
Ro Yo Mi
- 14,790
- 5
- 35
- 43