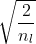I can't get TensorFlow RELU activations (neither tf.nn.relu nor tf.nn.relu6) working without NaN values for activations and weights killing my training runs.
I believe I'm following all the right general advice. For example I initialize my weights with
weights = tf.Variable(tf.truncated_normal(w_dims, stddev=0.1))
biases = tf.Variable(tf.constant(0.1 if neuron_fn in [tf.nn.relu, tf.nn.relu6] else 0.0, shape=b_dims))
and use a slow training rate, e.g.,
tf.train.MomentumOptimizer(0.02, momentum=0.5).minimize(cross_entropy_loss)
But any network of appreciable depth results in NaN for cost and and at least some weights (at least in the summary histograms for them). In fact, the cost is often NaN right from the start (before training).
I seem to have these issues even when I use L2 (about 0.001) regularization, and dropout (about 50%).
Is there some parameter or setting that I should adjust to avoid these issues? I'm at a loss as to where to even begin looking, so any suggestions would be appreciated!