Description
Rather than splitting on the characters, it would be easier to just match and capture each sentence substring
(?:<(?:(?:[a-z]+\s(?:[^>=]|='[^']*'|="[^"]*"|=[^'"\s]*)*"\s?\/?|\/[a-z]+)>)|(?:(?!<)(?:[^.?!]|[.?!](?=\S)))*)+[.?!]
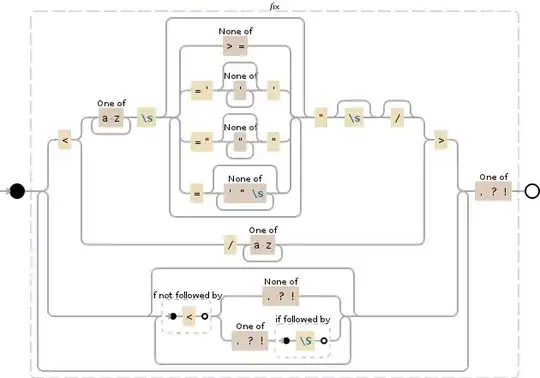
This regular expression will do the following:
- Match each sentence
- allow substrings like
F.C.B
- ignore html tags, but include them in the capture
Note: You'll need to escape all the \ so they look like \\
Example
Live Demo
https://regex101.com/r/fJ9zS0/3
Sample text
I am was trying to split paragraph to sentences. The paragraph can have a word like F.C.B also it includes some html tag like anchor and other tags. I was trying to use like below but it was not perfect separating my paragraph to the specific sentence by living the html tag as it is.
In 2004, he <a href="http://test.pic.org/jpeg."> received </a> national attention during his Party primary, his keynote address July, <a onmouseover=" fnRotator('I like droids. '); "> and </a> his election to the Senate in November. He began his presidential campaign in he won sufficient delegates in the Democratic Party primaries to receive the presidential nomination.
Sample Matches
Java Code Example:
import java.util.regex.Pattern;
import java.util.regex.Matcher;
class Module1{
public static void main(String[] asd){
String sourcestring = " ----your source string goes here----- ";
Pattern re = Pattern.compile("(?:<(?:(?:[a-z]+\\s(?:[^>=]|='[^']*'|=\"[^\"]*\"|=[^'\"\\s]*)*\"\\s?\\/?|\\/[a-z]+)>)|(?:(?!<)(?:[^.?!]|[.?!](?=\\S)))*)+[.?!]",Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);
Matcher m = re.matcher(sourcestring);
int mIdx = 0;
while (m.find()){
for( int groupIdx = 0; groupIdx < m.groupCount()+1; groupIdx++ ){
System.out.println( "[" + mIdx + "][" + groupIdx + "] = " + m.group(groupIdx));
}
mIdx++;
}
}
}
Sample Output
$matches Array:
(
[0] => Array
(
[0] => I am was trying to split paragraph to sentences.
[1] => The paragraph can have a word like F.C.B also it includes some html tag like anchor and other tags.
[2] => I was trying to use like below but it was not perfect separating my paragraph to the specific sentence by living the html tag as it is.
[3] =>
In 2004, he <a href="http://test.pic.org/jpeg."> received </a> national attention during his Party primary, his keynote address July, <a onmouseover=" fnRotator('I like droids. '); "> and </a> his election to the Senate in November.
[4] => He began his presidential campaign in he won sufficient delegates in the Democratic Party primaries to receive the presidential nomination.
)
)
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
(?: group, but do not capture (1 or more times
(matching the most amount possible)):
----------------------------------------------------------------------
< '<'
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[a-z]+ any character of: 'a' to 'z' (1 or
more times (matching the most amount
possible))
----------------------------------------------------------------------
\s whitespace (\n, \r, \t, \f, and " ")
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
[^>=] any character except: '>', '='
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=' '=\''
----------------------------------------------------------------------
[^']* any character except: ''' (0 or
more times (matching the most
amount possible))
----------------------------------------------------------------------
' '\''
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
=" '="'
----------------------------------------------------------------------
[^"]* any character except: '"' (0 or
more times (matching the most
amount possible))
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
= '='
----------------------------------------------------------------------
[^'"\s]* any character except: ''', '"',
whitespace (\n, \r, \t, \f, and "
") (0 or more times (matching the
most amount possible))
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
" '"'
----------------------------------------------------------------------
\s? whitespace (\n, \r, \t, \f, and " ")
(optional (matching the most amount
possible))
----------------------------------------------------------------------
\/? '/' (optional (matching the most
amount possible))
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
\/ '/'
----------------------------------------------------------------------
[a-z]+ any character of: 'a' to 'z' (1 or
more times (matching the most amount
possible))
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
> '>'
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
(?: group, but do not capture (0 or more
times (matching the most amount
possible)):
----------------------------------------------------------------------
(?! look ahead to see if there is not:
----------------------------------------------------------------------
< '<'
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[^.?!] any character except: '.', '?', '!'
----------------------------------------------------------------------
| OR
----------------------------------------------------------------------
[.?!] any character of: '.', '?', '!'
----------------------------------------------------------------------
(?= look ahead to see if there is:
----------------------------------------------------------------------
\S non-whitespace (all but \n, \r,
\t, \f, and " ")
----------------------------------------------------------------------
) end of look-ahead
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
)* end of grouping
----------------------------------------------------------------------
)+ end of grouping
----------------------------------------------------------------------
[.?!] any character of: '.', '?', '!'
----------------------------------------------------------------------