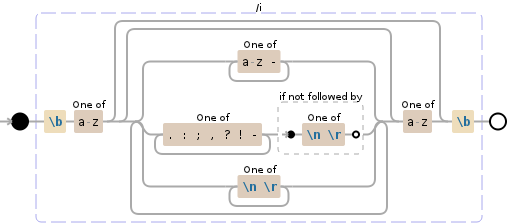
Description
\b(?:[a-z](?:[a-z\n\r.:;,?!-]*[a-z])?)\b
** Click for bigger image
This regular expression will do the following:
- Requires all words to start and end with
a-z, or be a single letter long
- Allows words to contain new line characters, or common punctuation like
.:;,?!-
- Words are not allowed to contain spaces
Example
Live Demo
https://regex101.com/r/bK4oO8/1
Sample text
How do I match text with a regular expres
sion ignoring punctuation and line breaks?
How do I do "find these words pos-
sibly separated but some non-alphanumeric characters"?
Sample Matches
MATCH 1
0. [0-3] `How`
MATCH 2
0. [4-6] `do`
MATCH 3
0. [7-8] `I`
MATCH 4
0. [9-14] `match`
MATCH 5
0. [15-19] `text`
MATCH 6
0. [20-24] `with`
MATCH 7
0. [25-26] `a`
MATCH 8
0. [27-34] `regular`
MATCH 9
0. [35-46] `expres
sion`
MATCH 10
0. [47-55] `ignoring`
MATCH 11
0. [56-67] `punctuation`
MATCH 12
0. [68-71] `and`
MATCH 13
0. [72-76] `line`
MATCH 14
0. [77-88] `breaks?
How`
MATCH 15
0. [89-91] `do`
MATCH 16
0. [92-93] `I`
MATCH 17
0. [94-96] `do`
MATCH 18
0. [98-102] `find`
MATCH 19
0. [103-108] `these`
MATCH 20
0. [109-114] `words`
MATCH 21
0. [115-125] `pos-
sibly`
MATCH 22
0. [126-135] `separated`
MATCH 23
0. [136-139] `but`
MATCH 24
0. [140-144] `some`
MATCH 25
0. [145-161] `non-alphanumeric`
MATCH 26
0. [162-172] `characters`
Explanation
NODE EXPLANATION
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
(?: group, but do not capture:
----------------------------------------------------------------------
[a-z] any character of: 'a' to 'z'
----------------------------------------------------------------------
(?: group, but do not capture (optional
(matching the most amount possible)):
----------------------------------------------------------------------
[a-z\n\r.:;,?!- any character of: 'a' to 'z', '\n'
]* (newline), '\r' (carriage return),
'.', ':', ';', ',', '?', '!', '-' (0
or more times (matching the most
amount possible))
----------------------------------------------------------------------
[a-z] any character of: 'a' to 'z'
----------------------------------------------------------------------
)? end of grouping
----------------------------------------------------------------------
) end of grouping
----------------------------------------------------------------------
\b the boundary between a word char (\w) and
something that is not a word char
----------------------------------------------------------------------
Extra Credit
If you also want to eliminate matches like #14 above, where you have a ? which is followed by a new line character. When in this configuration the ? should not be considered to be part of the word, where as a - followed by a new line is really a hyphen. Then you should consider this
\b(?:[a-z](?:(?:[a-z-]+|[.:;,?!-]+(?![\n\r])|[\n\r]+)*[a-z])?)\b
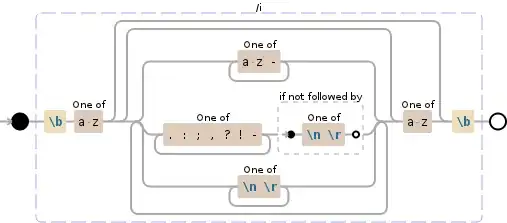
Live Demo: https://regex101.com/r/bK4oO8/2