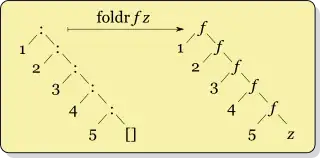
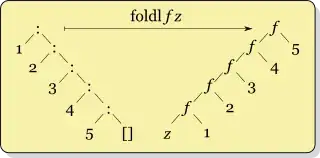
Firstly, Real World Haskell, which I am reading, says to never use foldl and instead use foldl'. So I trust it.
But I'm hazy on when to use foldr vs. foldl'. Though I can see the structure of how they work differently laid out in front of me, I'm too stupid to understand when "which is better." I guess it seems to me like it shouldn't really matter which is used, as they both produce the same answer (don't they?). In fact, my previous experience with this construct is from Ruby's inject and Clojure's reduce, which don't seem to have "left" and "right" versions. (Side question: which version do they use?)
Any insight that can help a smarts-challenged sort like me would be much appreciated!