I want to try parsing Excel XML Spreadsheet file with MSXML and XPath.
- https://technet.microsoft.com/en-us/magazine/2006.01.blogtales
- https://msdn.microsoft.com/en-us/library/aa140066.aspx
It has a root element of <Workbook xmlns.... xmlns....> and a bunch of next-level nodes <Worksheet ss:Name="xxxx">.
<?xml version="1.0" encoding="UTF-8"?>
<?mso-application progid="Excel.Sheet"?>
<Workbook xmlns="urn:schemas-microsoft-com:office:spreadsheet"
xmlns:o="urn:schemas-microsoft-com:office:office"
xmlns:x="urn:schemas-microsoft-com:office:excel"
xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"
xmlns:html="http://www.w3.org/TR/REC-html40">
....
<Worksheet ss:Name="Карточка">
....
</Worksheet>
<Worksheet ss:Name="Баланс">
...
...
...
</Worksheet>
</Workbook>
At a certain step I want to use XPath to get the very names of the worksheets.
NOTE: I do not want the get the names indirectly, that is to select those Worksheet nodes first and then enumerating them manually read their ss:Name child attribute nodes. That I can do, and it is not the topic here.
What I want is to utilize XPath flexibility: to directly fetch those ss:Name nodes without extra indirection layers.
procedure DoParseSheets( FileName: string );
var
rd: IXMLDocument;
ns: IDOMNodeList;
n: IDOMNode;
sel: IDOMNodeSelect;
ms: IXMLDOMDocument2;
ms1: IXMLDOMDocument;
i: integer;
s: string;
begin
rd := TXMLDocument.Create(nil);
rd.LoadFromFile( FileName );
if Supports(rd.DocumentElement.DOMNode,
IDOMNodeSelect, sel) then
begin
ms1 := (rd.DOMDocument as TMSDOMDocument).MSDocument;
if Supports( ms1, IXMLDOMDocument2, ms) then begin
ms.setProperty('SelectionNamespaces',
'xmlns="urn:schemas-microsoft-com:office:spreadsheet" '+
'xmlns:o="urn:schemas-microsoft-com:office:office" '+
'xmlns:x="urn:schemas-microsoft-com:office:excel" '+
'xmlns:ss="urn:schemas-microsoft-com:office:spreadsheet"');
ms.setProperty('SelectionLanguage', 'XPath');
end;
// ns := sel.selectNodes('/Workbook/Worksheet/@ss:Name/text()');
// ns := sel.selectNodes('/Workbook/Worksheet/@Name/text()');
ns := sel.selectNodes('/Workbook/Worksheet/@ss:Name');
// ns := sel.selectNodes('/Workbook/Worksheet/@Name');
// ns := sel.selectNodes('/Workbook/Worksheet');
for i := 0 to ns.length - 1 do
begin
n := ns.item[i];
s := n.nodeValue;
ShowMessage(s);
end;
end;
end;
When I use the dumbed down '/Workbook/Worksheet' query MSXML correctly return the nodes. But as soon as I add the attribute to the query - MSXML returns empty set.
Other XPath implementations like XMLPad Pro or http://www.freeformatter.com/xpath-tester.html correctly return the list of ss:Name attribute nodes. But MSXML does not.
What would be the XPath query text to help MSXML return the attribute nodes with given names ?
UPD. @koblik suggested a link to MS.Net selector (not MSXML one) and there are two examples there https://msdn.microsoft.com/en-us/library/ms256086(v=vs.110).aspx
- Example 1:
book[@style]- All elements with style attributes, of the current context. - Example 2:
book/@style- The style attribute for all elements of the current context.
That is the difference I told in the "NOTE" above: I don't need those books, I need the styles. I need attribute-nodes, not element-nodes!
And that Example 2 syntax is what MSXML seems to fail at.
UPD.2: One tester shows an interesting error claim:
The default (no prefix) Namespace URI for XPath queries is always '' and it cannot be redefined to 'urn:schemas-microsoft-com:office:spreadsheet'
I wonder if that claim about no default namespaces in XPath is really part of standard or just MSXML implementation limitation.
Then if to delete the default NS the results are how they should be:
Variant 1: 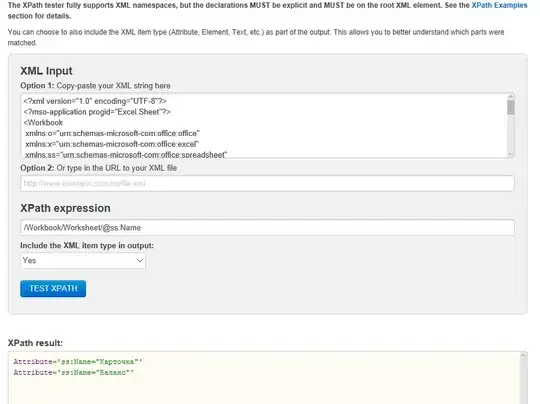 Variant 2:
Variant 2: 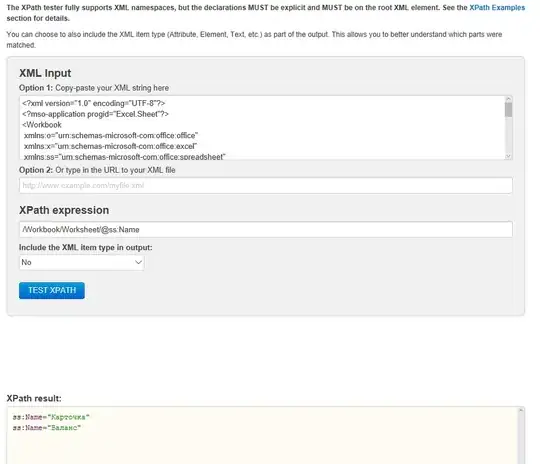
I wonder if that claim about no default namespaces in XPath is really part of standard or just MSXML implementation limitation.
UPD.3: Martin Honnen in comments explains that line: See w3.org/TR/xpath/#node-tests for XPath 1.0 (as supported by Microsoft MSXML), it clearly states "A QName in the node test is expanded into an expanded-name using the namespace declarations from the expression context. This is the same way expansion is done for element type names in start and end-tags except that the default namespace declared with xmlns is not used: if the QName does not have a prefix, then the namespace URI is null". So in XPath 1.0 a path like "/Workbook/Worksheet" selects elements of that name in no namespace.
UPD.4: So the selection works with '/ss:Workbook/ss:Worksheet/@ss:Name' XPath query, returning "ss:Name" attributes nodes directy. In the source XML document both default (no-prefix) and "ss:" namespaces are bound to the same URI. This URI is acknowledged by the XPath engine. But not the default namespace, which can not be redefined in MSXML XPath engine ( implementing 1.0 specs ). So to make it work, the default namespace should be mapped to another explicit prefix ( either already existing one or a newly created ) via URI and then that substitute prefix would be used in the XPath selection string. Since namespaces matching goes via URI not via prefixes it would not matter if prefixes used in the document and in the query match or not, they would be compared via their URIs.
ms.setProperty('SelectionLanguage', 'XPath');
ms.setProperty('SelectionNamespaces',
'xmlns:AnyPrefix="urn:schemas-microsoft-com:office:spreadsheet"');
and then
ns := sel.selectNodes(
'/AnyPrefix:Workbook/AnyPrefix:Worksheet/@AnyPrefix:Name' );
Thanks to Asbjørn and Martin Honnen for explaining those trivial after-the-fact but not obvious a priori relations.