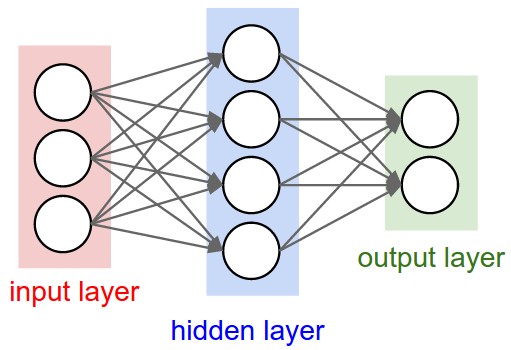
Take a look at this picture:
http://cs231n.github.io/assets/nn1/neural_net.jpeg
In your first picture you have only two layers:
- Input layers -> 784 neurons
- Output layer -> 10 neurons
Your model is too simple (w contains directly connections between the input and the output and b contains the bias terms).
With no hidden layer you are obtaining a linear classifier, because a linear combination of linear combinations is a linear combination again. The hidden layers are what include non linear transformations in your model.
In your second picture you have 3 layers, but you are confused the notation:
- The input layer is the vector x where you place an input data.
- Then the operation -> w -> +b -> f() -> is the conexion between the first layer and the second layer.
- The second layer is the vector where you store the result z=f(xw1+b1)
- Then softmax(zw2+b2) is the conexion between the second and the third layer.
- The third layer is the vector y where you store the final result y=softmax(zw2+b2).
- Cross entropy is not a layer is the cost function to train your neural network.
EDIT:
One more thing, if you want to obtain a non linear classifier you must add a non linear transformation in every hidden layer, in the example that I have described, if f() is a non linear function (for example sigmoid, softsign, ...):
z=f(xw1+b1)
If you add a non linear transformation only in the output layer (the softmax function that you have at the end) your outputs are still linear classifiers.


{kind=link}