I want to design a database which is described as follows: Each product has only one status at one time point. However, the status of a product can change during its life time. How could I design the relationship between product and status which can easily be queried all product of a specific status at current time? In addition, could anyone please give me some in-depth details about design database which related to time duration as problem above? Thanks for any help
Asked
Active
Viewed 2,015 times
5 Answers
8
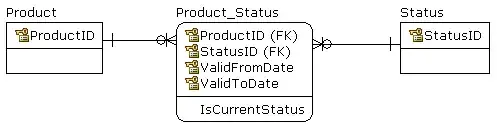
Here is a model to achieve your stated requirement.
Link to Time Series Data Model
Link to IDEF1X Notation for those who are unfamiliar with the Relational Modelling Standard.
Normalised to 5NF; no duplicate columns; no Update Anomalies, no Nulls.
When the Status of a Product changes, simply insert a row into ProductStatus, with the current DateTime. No need to touch previous rows (which were true, and remain true). No dummy values which report tools (other than your app) have to interpret.
The DateTime is the actual DateTime that the Product was placed in that Status; the "From", if you will. The "To" is easily derived: it is the DateTime of the next (DateTime > "From") row for the Product; where it does not exist, the value is the current DateTime (use ISNULL).
The first model is complete; (ProductId, DateTime) is enough to provide uniqueness, for the Primary Key. However, since you request speed for certain query conditions, we can enhance the model at the physical level, and provide:
An Index (we already have the PK Index, so we will enhance that first, before adding a second index) to support covered queries (those based on any arrangement of { ProductId | DateTime | Status } can be supplied by the Index, without having to go to the data rows). Which changes the Status::ProductStatus relation from Non-Identifying (broken line) to Identifying type (solid line).
The PK arrangement is chosen on the basis that most queries will be Time Series, based on Product⇢DateTime⇢Status.
The second index is supplied to enhance the speed of queries based on Status.
In the Alternate Arrangement, that is reversed; ie, we mostly want the current status of all Products.
In all renditions of ProductStatus, the DateTime column in the secondary Index (not the PK) is DESCending; the most recent is first up.
I have provided the discussion you requested. Of course, you need to experiment with a data set of reasonable size, and make your own decisions. If there is anything here that you do not understand, please ask, and I will expand.
Responses to Comments
Report all Products with Current State of 2
SELECT ProductId,
Description
FROM Product p,
ProductStatus ps
WHERE p.ProductId = ps.ProductId -- Join
AND StatusCode = 2 -- Request
AND DateTime = ( -- Current Status on the left ...
SELECT MAX(DateTime) -- Current Status row for outer Product
FROM ProductStatus ps_inner
WHERE p.ProductId = ps_inner.ProductId
)ProductIdis Indexed, leading col, both sidesDateTimein Indexed, 2nd col in Covered Query OptionStatusCodeis Indexed, 3rd col in Covered Query OptionSince
StatusCodein the Index is DESCending, only one fetch is required to satisfy the inner querythe rows are required at the same time, for the one query; they are close together (due to Clstered Index); almost always on the same page due to the short row size.
This is ordinary SQL, a subquery, using the power of the SQL engine, Relational set processing. It is the one correct method, there is nothing faster, and any other method would be slower. Any report tool will produce this code with a few clicks, no typing.
Two Dates in ProductStatus
Columns such as DateTimeFrom and DateTimeTo are gross errors. Let's take it in order of importance.
It is a gross Normalisation error. "DateTimeTo" is easily derived from the single DateTime of the next row; it is therefore redundant, a duplicate column.
- The precision does not come into it: that is easily resolved by virtue of the DataType (DATE, DATETIME, SMALLDATETIME). Whether you display one less second, microsecond, or nanosecnd, is a business decision; it has nothing to do with the data that is stored.
Implementing a DateTo column is a 100% duplicate (of DateTime of the next row). This takes twice the disk space. For a large table, that would be significant unnecessary waste.
Given that it is a short row, you will need twice as many logical and physical I/Os to read the table, on every access.
And twice as much cache space (or put another way, only half as many rows would fit into any given cache space).
By introducing a duplicate column, you have introduced the possibility of error (the value can now be derived two ways: from the duplicate DateTimeTo column or the DateTimeFrom of the next row).
This is also an Update Anomaly. When you update any DateTimeFrom is Updated, the DateTimeTo of the previous row has to be fetched (no big deal as it is close) and Updated (big deal as it is an additional verb that can be avoided).
"Shorter" and "coding shortcuts" are irrelevant, SQL is a cumbersome data manipulation language, but SQL is all we have (Just Deal With It). Anyone who cannot code a subquery really should not be coding. Anyone who duplicates a column to ease minor coding "difficulty" really should not be modelling databases.
Note well, that if the highest order rule (Normalisation) was maintained, the entire set of lower order problems are eliminated.
Think in Terms of Sets
Anyone having "difficulty" or experiencing "pain" when writing simple SQL is crippled in performing their job function. Typically the developer is not thinking in terms of sets and the Relational Database is set-oriented model.
For the query above, we need the Current DateTime; since ProductStatus is a set of Product States in chronological order, we simply need the latest, or MAX(DateTime) of the set belonging to the Product.
Now let's look at something allegedly "difficult", in terms of sets. For a report of the duration that each Product has been in a particular State: the DateTimeFrom is an available column, and defines the horizontal cut-off, a sub set (we can exclude earlier rows); the DateTimeTo is the earliest of the sub set of Product States.
SELECT ProductId,
Description,
[DateFrom] = DateTime,
[DateTo] = (
SELECT MIN(DateTime) -- earliest in subset
FROM ProductStatus ps_inner
WHERE p.ProductId = ps_inner.ProductId -- our Product
AND ps_inner.DateTime > ps.DateTime -- defines subset, cutoff
)
FROM Product p,
ProductStatus ps
WHERE p.ProductId = ps.ProductId
AND StatusCode = 2 -- RequestThinking in terms of getting the next row is row-oriented, not set-oriented processing. Crippling, when working with a set-oriented database. Let the Optimiser do all that thinking for you. Check your SHOWPLAN, this optimises beautifully.
Inability to think in sets, thus being limited to writing only single-level queries, is not a reasonable justification for: implementing massive duplication and Update Anomalies in the database; wasting online resources and disk space; guaranteeing half the performance. Much cheaper to learn how to write simple SQL subqueries to obtain easily derived data.
PerformanceDBA
- 32,198
- 10
- 64
- 90
-
Could you please give an SQL query example that select all product of which current status is 2. Thanks – coolkid Nov 08 '10 at 04:22
-
I have a solution that use nested query. Is there any shorter and faster query in this case? – coolkid Nov 08 '10 at 04:36
-
@CoolKid. Sorry, I was not notified re Comments. – PerformanceDBA Nov 10 '10 at 10:44
-
yes, I mean subquery which U suggested. Thanks anyway. Sorry because I cannot choose many solutions :) – coolkid Nov 11 '10 at 17:11
-
@PerformanceDBA: while I have no problem with this solution (which I have worked with in the past), and acknowledge some of the advantages you state, I am interested in your claim that it also performs better in queries than the from/to date method. It generally wouldn't in Oracle, in my experience, so I am curious how the DBMSs you know would process such a query and what the relative timings would be? – Tony Andrews Dec 06 '10 at 12:03
-
1@Tony: 1) We already know from the other recent thread that Oracle cacks itself doing subqueries. (BTW That answers many questions I had in the past re why Oracle demanded certain changes for benchmark requirements. So it is no wonder that the Oracle boys implement duplicate columns in order to avoid them. So it is not accurate to say Oracle would perform the BETWEEN version at the same speed; the fact is oracle **can't** perform the Subquery version. 2) Sybase, DB2 & MS have no problem with subqueries (ok MS broke it badly in 2008, but "wait for the next SP".) – PerformanceDBA Dec 06 '10 at 16:03
-
13) I have provided the structure of teh required (typical) subqueries in my answer. I am quite familiar with the query plans, same as recently posted on the other question. DB2 & Sybase have very mature, Optimisers that produce highly normalised QPs. Not sure if that answer your questn ? Would you like me to run a test ? – PerformanceDBA Dec 06 '10 at 16:08
-
Oracle doesn't have a problem with subqueries in general, AFAIK - it has a problem with SCALAR subqueries in the SELECT clause. I'm still curious as to **How** Sybase, DB2 or MS would actually process your query - how computing the maximum DateTime for each group and selecting the rows that correspond is quicker than simply filtering the rows that surround a date. I'm not saying it can't be, I would just like to understand how. – Tony Andrews Dec 06 '10 at 16:09
-
Yes I'd be interested in test results. – Tony Andrews Dec 06 '10 at 16:10
-
1@Tony. 1) But these **are** scalar subqueires ! 3) you do realise that the set from which the MAX() is extracted is (a) small (b) correlated, therefore (c) it will be accomplished in the same scan and (d) almost certainly in cache, don't you. 4) Ok, so you want the LIO & processing tested, like the last test, PIO is not relevant ? Which of the 3 DDL Options (refer link, I suggest DateTime as not the leading column, otherwise there is no challenge) you want ? And pls email me the exact flattened query you want with the BETWEEN or whatever, it is late and I can't think in non-set terms, sorry. – PerformanceDBA Dec 06 '10 at 17:03
-
1) True, I mean Oracle has a specific problem with scalar subqueries in the SELECT clause, not in the WHERE clause. 3) (3?!) yes, yes, no and yes. Oracle **doesn't** perform it in the same scan, perhaps that is the nub of my lack of understanding of these other DBMSs. 4) Yes that's fine. Whichever DDL option is best for the "current status" query - the 3rd one? Flattened query: SELECT p.ProductId, p.Description, ps.DateFrom, ps.DateTo FROM Product p, ProductStatus2 ps WHERE p.ProductId = ps.ProductId AND ps.StatusCode = 2 AND SYSDATE BETWEEN ps.DateFrom AND ps.DateTo – Tony Andrews Dec 06 '10 at 17:16
-
1@Tony: 1) But these **are** scalar subqueries in the SELECT list ! 3) Aha. Any combination of: examine Stats Summaries from the last test; or examine the Query Plans I emailed you; or wait for test results. For your side, I feel if you close the outstanding issue from last test, it would benefit your incremental knowledge of said subject. *Prepare yourself, we're at the gate, I'm gonna the wipe the floor, with your old mate.* 4) No, that has DateTime as the leading column, so no challenge at all, let's get Sybase to work for the money; I suggest the 2nd; minus the second Index. – PerformanceDBA Dec 06 '10 at 22:09
-
Sorry, I was referring to your first query "Report all Products with Current State of 2", that does not have a scalar subquery in the SELECT list, it has a subquery in the WHERE clause. That is the query whose performance I am interested in. – Tony Andrews Dec 07 '10 at 09:25
-
2The constraints of the comment format are making this harder than it should be, so I have raised a separate question: http://stackoverflow.com/questions/4375192/performance-of-different-aproaches-to-time-based-data – Tony Andrews Dec 07 '10 at 09:41
-
1@Tony: Aha, yes. Ok, and the subquery in the WHERE clause is a table subquery (or inline as Oracle calls it). – PerformanceDBA Dec 08 '10 at 15:12
2
"In addition, could anyone please give me some in-depth details about design database which related to time duration as problem above?"
Well, there exists a 400-page book entitled "Temporal Data and the Relational Model" that addresses your problem.
That book also addresses numerous problems that the other responders have not addressed in their responses, for lack of time or for lack of space or for lack of knowledge.
The introduction of the book also explicitly states that "this book is not about technology that is (commercially) available to any user today.".
All I can observe is that users wanting temporal features from SQL systems are, to put it plain and simple, left wanting.
PS
Even if those 400 pages could be "compressed a bit", I hope you don't expect me to give a summary of the entire meaningful content within a few paragraphs here on SO ...
Erwin Smout
- 18,113
- 4
- 33
- 52
1
tables similar to these:
product
-----------
product_id
status_id
name
status
-----------
status_id
name
product_history
---------------
product_id
status_id
status_time
then write a trigger on product to record the status and timestamp (sysdate) on each update where the status changes
Randy
- 16,480
- 1
- 37
- 55
1
Damir Sudarevic
- 21,891
- 3
- 47
- 71
-
2As with James, ValidToDate is a redundant, it can be derived easily. IsCurrentStatus is likewise redundat, and can be derived easily ( Max(ValidFromDate) ). – PerformanceDBA Nov 06 '10 at 22:33
-
@PerformanceDBA -- yes, but it is way faster and simpler to say `WHERE IsCurrentStatus = 1` than to derive it. – Damir Sudarevic Nov 07 '10 at 14:04
-
1Maybe acceptable in some (bloated) DWs. But in an RDB, it is not way faster, or even a little faster. And it is wrong. 100% duplication of a column, unnecessarily, is ridiculous, double the disk space & physical I/O. Based on your PK, the rows are next to each other and guaranteed to be on the same page, and in cache at the same moment. Only half of your table would fit into any given cache size, therefore twice as slow for logical I/O as well. – PerformanceDBA Nov 10 '10 at 11:27
0
Google "bi-temporal databases" and "slowly changing dimensions".
These are two names for esentially the same pattern.
You need to add two timestamp columns to your product table "VALID_FROM" and "VALID_TO".
When your product status changes you add a NEW row with "VALID_FROM" of now() some other known effective data/time and set the "VALID_TO" to 9999-12-31 23:59:59 or some other date ridiculously far into the future. You also need to zap the "9999-12-31..." date on the previously current row to the current "VALID_FROM" time - 1 microsecond.
You can then easily query the product status at any given time.
James Anderson
- 27,109
- 7
- 50
- 78
-
2@James: I have no problem with the concept of your answer. But the second column is a 100% duplicate (the table will be twice as large as it needs to be): it can be derived from the first column of the next row. Further, if the second column is removed, microseconds, etc, do not come into consideration; whatever datatype is relevant (DATE, SMALLDATETIME, DATETIME) can be used. – PerformanceDBA Nov 06 '10 at 22:28
-
Yes the "VALID_TO" can be derived but the SQL for doing so is a real pain! With the VALID_TO column the SQL for finding the valid row for a given date is much easier! – James Anderson Nov 09 '10 at 02:30
-
1@; table twice as large; or half as much fitting into the same cache space; twice the physical disk I/os.: Maybe I am missing something, can you please post the "painful" SQL to derive the VaidTo value. In any case, that is not a valid or reasonable justification for 100% duplication – PerformanceDBA Nov 10 '10 at 10:04
-
With valid to the SQL is a simple bracketing of dates "Select stuff from tab where valid_from < mydate and valid_to > mydate". With only VALID_FROM you are stuck with something like "SELECT STUFF FROM TAB WHERE VALID_FROM > mydate order by VALID_FROM for first row only". Also you miss out on the "VALID_TO = '9999-12-31' " shortcut to get all current rows. – James Anderson Nov 11 '10 at 01:30
-
1@James: I understood all that. 1. coding "shortcuts", particularly where the value is easily derived, is not a valid justification, for 100% duplication of a column. 2. If the table is large, that's twice the large space. 3. Half the performance. 4. You have broken Normalisation. 5. You have introduced the possibility of error (value can now be derived two ways). Unacceptable and incorrect advice. -1 for arguing without fixing after I pointed it out. – PerformanceDBA Nov 12 '10 at 23:21
-
1@James: Also, adding your two columns to the PRODUCT table will allow only the current status. You need a child table for the historic product status. – PerformanceDBA Nov 12 '10 at 23:31
-
Not so the primary key becomes ID,VALID_FROM,VALID_TO so the status at an given time is available – James Anderson Nov 19 '10 at 07:40
-
2@James. OMG, so you've duplicated the entire Product table times the no of Product Versions. Hilarious. Let me guess, only the current Product version, with the Dummy Value of 9999-12-31 has the real Product columns, everything else in the table (expect historic Status and time range) is false! That's what you call database "design", eh. "Normalised", no doubt. "High Performance" via massive duplication. All for a shortcut. – PerformanceDBA Nov 25 '10 at 08:14
-
@PerformanceDBA:I agree with your reasoning regarding Update Anomalies and data duplication and you have clearly paid attention to the performance implications by considering covered queries, cache utilisation etc... I guess the tension comes from the Kimball Dimensional Modeling literature where the common advice is to denormalise in favour of a simple star schema and simple joins. I want to build on experience where possible rather than retesting things for myself. Are there any contexts where a Kimball Type 2 dimension with surrogate key would be preferable to a proper normalised design? – snth Nov 30 '10 at 11:15
-
@PerformanceDBA: Do you systems run on a 386 8MB Ram with 60MB of disk storage. If not your performance/space concerns are pretty much irrelevent fo ra system of this size. – James Anderson Dec 07 '10 at 01:16
-
2@James: The question is a database question, not a data warehouse question. Massively inefficient designs which *may* be acceptable in a (read intensive) DW, are not appropriate for modern databases. Most of my servers are SPARCs, at the rate your are going, you will never see one; with the price we pay, we do not allow silly things like 100% duplication. Fat people do not participate in the Olympics. So this Kimball guy actually *advises* duplication of atomic facts, does he ? Has he actually seen a database ? Meaning it sounds like he started with a non-database, and made it better. – PerformanceDBA Dec 09 '10 at 12:53