I'm new in C# and data scraping and I'm not sure what should I do. I was planning to search some keywords in google then get the title and description and url of those in search results then use the url in seocheki.net then extract the data too. How should I do it?
I still don't know what to do to extract google search result yet so I tried to to get the data in seocheki.
I tried to use HTMLAgilityPack to get the data in seocheki
private async Task<List<Seocheki>> ResultFromSeocheki(int pageNum)
{
string url = "http://seocheki.net/site-check.php?u=http%3A%2F%2Fwww.gamerankings.com%2Fbrowse.html";
var doc = await Task.Factory.StartNew(() => web.Load(url));
var titleNodes = doc.DocumentNode.SelectNodes("//*[@id=\"td-title\"]");
var descNodes = doc.DocumentNode.SelectNodes("//*[@id=\"td-desc\"]");
var keywordNodes = doc.DocumentNode.SelectNodes("//*[@id=\"td-kw\"]");
var h1Nodes = doc.DocumentNode.SelectNodes("//*[@id=\"td-h1\"]");
var title = titleNodes.Select(node => node.InnerText).ToList();
var desc = descNodes.Select(node => node.InnerText).ToList();
var keyword = keywordNodes.Select(node => node.InnerText).ToList();
var h1 = h1Nodes.Select(node => node.LastChild.InnerText).ToList();
}
but this is the result
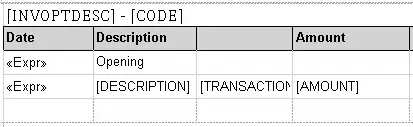
How to scrape the data? HTMLAgilityPack doesn't seem to work to me.