In NVIDIA's paper "End to End Learning for Self-Driving Cars" there's an illustration showing the activation of first-layer feature maps:
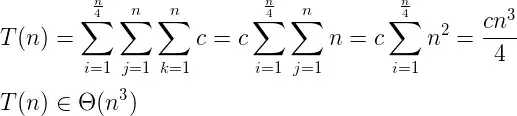
I'm trying to recreate this with the Comma AI model, but the only visualisation tools I've found are Keras' instructions for gradient ascent and descent, rather than simply viewing activations. what should I be looking for?
EDIT IN RESPONSE TO COMMENT
I tried implementing the code in this answer using the below code:
from keras import backend as K
import json
from keras.models import model_from_json
with open('outputs/steering_model/steering_angle.json', 'r') as jfile:
z = json.load(jfile)
model = model_from_json(z)
print("Loaded model")
model.load_weights('outputs/steering_model/steering_angle.keras')
print("Loaded weights")
img_width = 320
img_height = 160
outputs = [layer.output for layer in model.layers] # all layer outputs
functors = [K.function([inp]+ [K.learning_phase()], [out]) for out in outputs] # evaluation functions
# Testing
test = np.random.random((1, 3, img_width, img_height))
layer_outs = [func([test, 1.]) for func in functors]
print layer_outs
This give the following output error:
Using Theano backend.
Loaded model
Loaded weights
Traceback (most recent call last):
File "vis-layers.py", line 22, in <module>
layer_outs = [func([test, 1.]) for func in functors]
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/backend/theano_backend.py", line 959, in __call__
return self.function(*inputs)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/compile/function_module.py", line 871, in __call__
storage_map=getattr(self.fn, 'storage_map', None))
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/gof/link.py", line 314, in raise_with_op
reraise(exc_type, exc_value, exc_trace)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/compile/function_module.py", line 859, in __call__
outputs = self.fn()
ValueError: Shape mismatch: x has 49152 cols (and 1 rows) but y has 12800 rows (and 512 cols)
Apply node that caused the error: Dot22(Elemwise{Composite{Switch(GT(i0, i1), i0, expm1(i0))}}[(0, 0)].0, dense_1_W)
Toposort index: 50
Inputs types: [TensorType(float32, matrix), TensorType(float32, matrix)]
Inputs shapes: [(1, 49152), (12800, 512)]
Inputs strides: [(196608, 4), (2048, 4)]
Inputs values: ['not shown', 'not shown']
Outputs clients: [[Elemwise{Add}[(0, 0)](Dot22.0, InplaceDimShuffle{x,0}.0)]]
I thought this might be a problem with th vs tf dimensions, so tried changing the test input to:
test = np.random.random((1, img_height, img_width, 3))
which gave the following error:
Using Theano backend.
Loaded model
Loaded weights
Traceback (most recent call last):
File "vis-layers.py", line 22, in <module>
layer_outs = [func([test, 1.]) for func in functors]
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/backend/theano_backend.py", line 959, in __call__
return self.function(*inputs)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/compile/function_module.py", line 871, in __call__
storage_map=getattr(self.fn, 'storage_map', None))
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/gof/link.py", line 314, in raise_with_op
reraise(exc_type, exc_value, exc_trace)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/theano/compile/function_module.py", line 859, in __call__
outputs = self.fn()
ValueError: CorrMM images and kernel must have the same stack size
Apply node that caused the error: CorrMM{half, (4, 4)}(Elemwise{Composite{(i0 + (i1 * i2))}}.0, Subtensor{::, ::, ::int64, ::int64}.0)
Toposort index: 9
Inputs types: [TensorType(float32, 4D), TensorType(float32, 4D)]
Inputs shapes: [(1, 320, 160, 3), (16, 3, 8, 8)]
Inputs strides: [(2250000, 6000, 12, 4), (768, 256, -32, -4)]
Inputs values: ['not shown', 'not shown']
Outputs clients: [[Subtensor{int64:int64:int8, int64:int64:int8, int64:int64:int8, int64:int64:int8}(CorrMM{half, (4, 4)}.0, ScalarFromTensor.0, ScalarFromTensor.0, Constant{1}, Constant{0}, Constant{16}, Constant{1}, ScalarFromTensor.0, ScalarFromTensor.0, Constant{1}, ScalarFromTensor.0, ScalarFromTensor.0, Constant{1})]]
Backtrace when the node is created(use Theano flag traceback.limit=N to make it longer):
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/utils/layer_utils.py", line 43, in layer_from_config
return layer_class.from_config(config['config'])
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/models.py", line 1091, in from_config
model.add(layer)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/models.py", line 332, in add
output_tensor = layer(self.outputs[0])
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/topology.py", line 572, in __call__
self.add_inbound_node(inbound_layers, node_indices, tensor_indices)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/topology.py", line 635, in add_inbound_node
Node.create_node(self, inbound_layers, node_indices, tensor_indices)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/engine/topology.py", line 166, in create_node
output_tensors = to_list(outbound_layer.call(input_tensors[0], mask=input_masks[0]))
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/layers/convolutional.py", line 475, in call
filter_shape=self.W_shape)
File "/home/ubuntu/anaconda2/lib/python2.7/site-packages/keras/backend/theano_backend.py", line 1508, in conv2d
filter_shape=filter_shape)
EDIT: Output of model.summary()
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
lambda_1 (Lambda) (None, 3, 160, 320) 0 lambda_input_1[0][0]
____________________________________________________________________________________________________
convolution2d_1 (Convolution2D) (None, 16, 40, 80) 3088 lambda_1[0][0]
____________________________________________________________________________________________________
elu_1 (ELU) (None, 16, 40, 80) 0 convolution2d_1[0][0]
____________________________________________________________________________________________________
convolution2d_2 (Convolution2D) (None, 32, 20, 40) 12832 elu_1[0][0]
____________________________________________________________________________________________________
elu_2 (ELU) (None, 32, 20, 40) 0 convolution2d_2[0][0]
____________________________________________________________________________________________________
convolution2d_3 (Convolution2D) (None, 64, 10, 20) 51264 elu_2[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 12800) 0 convolution2d_3[0][0]
____________________________________________________________________________________________________
dropout_1 (Dropout) (None, 12800) 0 flatten_1[0][0]
____________________________________________________________________________________________________
elu_3 (ELU) (None, 12800) 0 dropout_1[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 512) 6554112 elu_3[0][0]
____________________________________________________________________________________________________
dropout_2 (Dropout) (None, 512) 0 dense_1[0][0]
____________________________________________________________________________________________________
elu_4 (ELU) (None, 512) 0 dropout_2[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 1) 513 elu_4[0][0]
====================================================================================================
Total params: 6,621,809
Trainable params: 6,621,809
Non-trainable params: 0
____________________________________________________________________________________________________
EDIT: DEBUGGING WITH SINGLE LAYER
In order to debug the issue with input shapes, I rewrote the script for a single layer:
from keras import backend as K
import numpy as np
import json
from keras.models import model_from_json
with open('outputs/steering_model/steering_angle.json', 'r') as jfile:
z = json.load(jfile)
model = model_from_json(z)
print("Loaded model")
model.load_weights('outputs/steering_model/steering_angle.keras')
print("Loaded weights")
layer_name = 'lambda_1'
img_width = 160
img_height = 320
inp = model.input
layer_idx = [idx for idx, layer in enumerate(model.layers) if layer.name == layer_name][0]
output = model.layers[layer_idx].output
functor = K.function([inp]+ [K.learning_phase()], output) # evaluation function
# Testing
test = np.random.random((1, img_height, img_width, 3))
layer_out = functor([test, 1.])
print layer_out
The output from this is as follows:
Using Theano backend.
Loaded model
Loaded weights
[[[[-0.99223709 -0.99468529 -0.99318016]
[-0.99725926 -0.9924705 -0.9994905 ]
[-0.99380279 -0.99291307 -0.99927235]
...,
[-0.99361622 -0.99258155 -0.99954134]
[-0.99748689 -0.99217939 -0.99918425]
[-0.99475586 -0.99366009 -0.992827 ]]
[[-0.99330682 -0.99756712 -0.99795902]
[-0.99421203 -0.99240923 -0.99438184]
[-0.99222761 -0.99425066 -0.99886942]
...,
[-0.99329156 -0.99460274 -0.99994165]
[-0.99763876 -0.99870259 -0.9998613 ]
[-0.99962425 -0.99702215 -0.9943046 ]]
[[-0.99947125 -0.99577188 -0.99294066]
[-0.99582225 -0.99568367 -0.99345332]
[-0.99823713 -0.99376178 -0.99432898]
...,
[-0.99828976 -0.99264622 -0.99669623]
[-0.99485278 -0.99353015 -0.99411404]
[-0.99832171 -0.99390954 -0.99620205]]
...,
[[-0.9980613 -0.99474132 -0.99680966]
[-0.99378282 -0.99288809 -0.99248403]
[-0.99375945 -0.9966079 -0.99440354]
...,
[-0.99634677 -0.99931824 -0.99611002]
[-0.99781156 -0.99990571 -0.99249381]
[-0.9996115 -0.99991143 -0.99486816]]
[[-0.99839222 -0.99690026 -0.99410695]
[-0.99551272 -0.99262673 -0.99934679]
[-0.99432331 -0.99822938 -0.99294668]
...,
[-0.99515969 -0.99867356 -0.9926796 ]
[-0.99478716 -0.99883151 -0.99760127]
[-0.9982425 -0.99547088 -0.99658638]]
[[-0.99240851 -0.99792403 -0.99360847]
[-0.99226022 -0.99546915 -0.99411654]
[-0.99558711 -0.9960795 -0.9993062 ]
...,
[-0.99745959 -0.99276334 -0.99800634]
[-0.99249429 -0.99748743 -0.99576926]
[-0.99531293 -0.99618822 -0.99997312]]]]
However, attempting the same on the first convolutional layer (convolution2d_1) with an 80x40 image returns the same error:
ValueError: CorrMM images and kernel must have the same stack size
Apply node that caused the error: CorrMM{half, (4, 4)}(Elemwise{Composite{(i0 + (i1 * i2))}}.0, Subtensor{::, ::, ::int64, ::int64}.0)
Toposort index: 9
Inputs types: [TensorType(float32, 4D), TensorType(float32, 4D)]
Inputs shapes: [(1, 40, 80, 3), (16, 3, 8, 8)]
Inputs strides: [(38400, 960, 12, 4), (768, 256, -32, -4)]
Inputs values: ['not shown', 'not shown']
Outputs clients: [[Subtensor{int64:int64:int8, int64:int64:int8, int64:int64:int8, int64:int64:int8}(CorrMM{half, (4, 4)}.0, ScalarFromTensor.0, ScalarFromTensor.0, Constant{1}, Constant{0}, Constant{16}, Constant{1}, ScalarFromTensor.0, ScalarFromTensor.0, Constant{1}, ScalarFromTensor.0, ScalarFromTensor.0, Constant{1})]]
EDIT: OUTPUT LAYER DATA AS IMAGE
The following code replaces the random image with a loaded one, and takes the layer output and saves it as an image:
input_img_data = imread(impath+'.png').astype(np.float32)
# change image to 4d theano array
test = np.expand_dims(input_img_data,axis=0)
print test.shape
layer_out = functor([test, 1.])
img = Image.fromarray(layer_out[0,:,:,:], 'RGB')
img.save('activ_%s_%s.png' % (layer_name,impath))
print("Created Image")