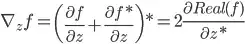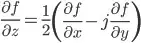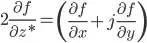Let z is a complex variable, C(z) is its conjugation. In complex analysis theory, the derivative of C(z) w.r.t z don't exist. But in tesnsorflow, we can calculate dC(z)/dz and the result is just 1. Here is an example:
x = tf.placeholder('complex64',(2,2))
y = tf.reduce_sum(tf.conj(x))
z = tf.gradients(y,x)
sess = tf.Session()
X = np.random.rand(2,2)+1.j*np.random.rand(2,2)
X = X.astype('complex64')
Z = sess.run(z,{x:X})[0]
The input X is
[[0.17014372+0.71475762j 0.57455420+0.00144318j]
[0.57871044+0.61303568j 0.48074263+0.7623235j ]]
and the result Z is
[[1.-0.j 1.-0.j]
[1.-0.j 1.-0.j]]
I don't understand why the gradient is set to be 1? And I want to know how tensorflow handles the complex gradients in general.