I'm new to R and Rstudio, so this may seem kinda odd.
I'm currently trying to eliminate some rows from a very big (roughly 400.000 rows) .CSV file, but I face some problems.
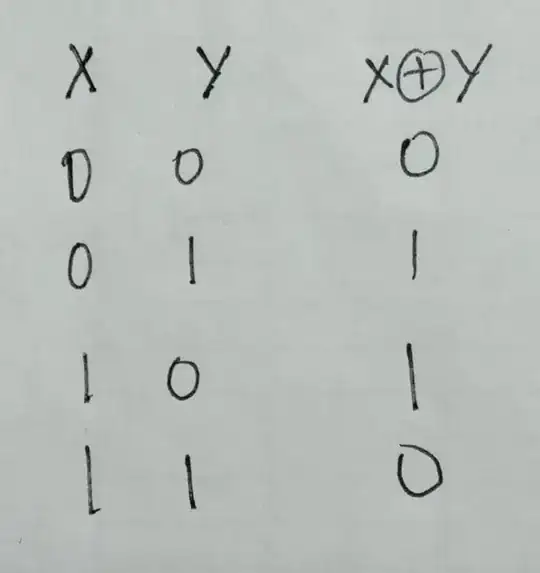
Here is the output I want (In this example, we deleted the row 6:
1- When I execute:
tablename <- tablename[c(-row1, -row2), ]
for, let's say 7 rows, it works just fine for the first time I execute it. Then, if I execute the same syntax for another row that I want to delete. For example:
tablename <- tablename[c(-row3, -row4), ]" )
it seems that it dont delete the rows that I specified.
2- Because of the problem described above, I tried to create a 'super' syntax that has all the rows I want to delete. For example:
tablename <- tablename[c(-row1, -row2, ..., -row299, -row300), ]
The thing with this, is that it appears to do nothing (again). It just appears a '+' in the console, instead of the ' > '.
The last option I have, is to delete all the unwanted rows in the .CSV file with the Search Keyword option in WordPad, but it is not viable, as long as it would take me like 9 hours.