I'm parsing from tweets data which is json format and compressed with gzip.
Here's my code:
###Preprocessing
##Importing:
import os
import gzip
import json
import pandas as pd
from pandas.io.json import json_normalize
##Variables:
#tweets: DataFrame for merging. empty
tweets = pd.DataFrame()
idx = 0
#Parser provides parsing the input data and return as pd.DataFrame format
###Directory reading:
##Reading whole directory from
for root, dirs, files in os.walk('D:/twitter/salathe-us-twitter/11April1'):
for file in files:
#file tracking, #Memory Checker:
print(file, tweets.memory_usage())
# ext represent the extension.
ext = os.path.splitext(file)[-1]
if ext == '.gz':
with gzip.open(os.path.join(root, file), "rt") as tweet_file:
# print(tweet_file)
for line in tweet_file:
try:
temp = line.partition('|')
date = temp[0]
tweet = json.loads(temp[2])
if tweet['user']['lang'] == 'en' and tweet['place']['country_code'] == 'US':
# Mapping for memory.
# The index must be sequence like series.
# temporary solve by listlizing int values: id, retweet-count.
#print(tweet)
temp_dict = {"id": tweet["user"]["id"],
"text": tweet["text"],
"hashtags": tweet["entities"]["hashtags"][0]["text"],
"date":[int(date[:8])]}
#idx for DataFrame ix
temp_DF = pd.DataFrame(temp_dict, index=[idx])
tweets = pd.concat([tweets, temp_DF])
idx += 1
except:
continue
else:
with open(os.path.join(root, file), "r") as tweet_file:
# print(tweets_file)
for line in tweet_file:
try:
temp = line.partition('|')
#date
date = temp[0]
tweet = json.loads(temp[2])
if tweet['user']['lang'] == 'en' and tweet['place']['country_code'] == 'US':
# Mapping for memory.
# The index must be sequence like series.
# temporary solve by listlizing int values: id, retweet-count.
#print(tweet)
temp_dict = {"id": [tweet["user"]["id"]],
"text": tweet["text"],
"hashtags": tweet["entities"]["hashtags"][0]["text"],
"date":[int(date[:8])]}
temp_DF = pd.DataFrame(temp_dict, index=[idx])
tweets = pd.concat([tweets, temp_DF])
idx += 1
except:
continue
##STORING PROCESS.
store = pd.HDFStore('D:/Twitter_project/mydata.h5')
store['11April1'] = tweets
store.close()
My code can be distinct to 3 parts: reading, processing to select columns and storing. What I interest is that I want to parsing them more faster. So here's my questions: It's too slow. How could it be much faster? read by pandas json reader? Well I guess it's much faster than normal json.loads... But! Because my raw tweet data have multi-index values. So pandas read_json didn't work. And overally, I'm not sure I implemented my code well. Are there something problems or better way? I'm kinda new on programming. So please teach me to do much better.
{kind=link}
p.s The computer just turned off while the code is running. Why this happen? Memory problem?
Thanks to read this.
p.p.s
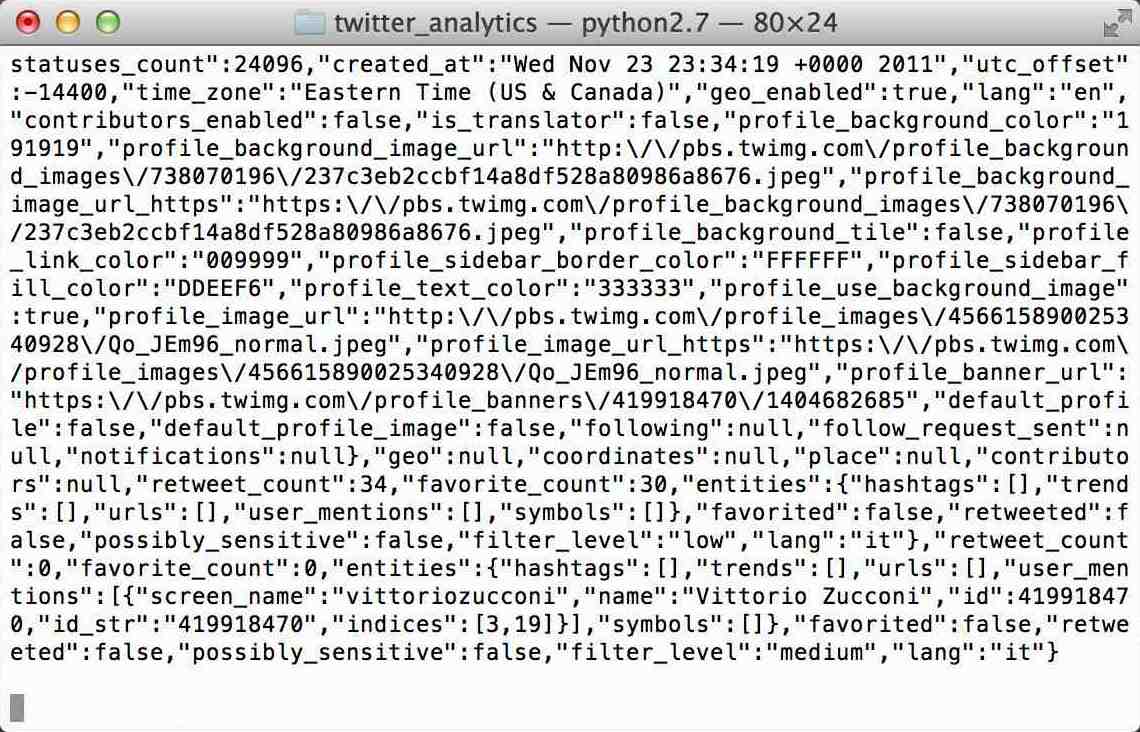
20110331010003954|{"text":"#Honestly my toe still aint healed im suppose to be in that boot still!!!","truncated":false,"in_reply_to_user_id":null,"in_reply_to_status_id":null,"favorited":false,"source":"web","in_reply_to_screen_name":null,"in_reply_to_status_id_str":null,"id_str":"53320627431550976","entities":{"hashtags":[{"text":"Honestly","indices":[0,9]}],"user_mentions":[],"urls":[]},"contributors":null,"retweeted":false,"in_reply_to_user_id_str":null,"place":{"country_code":"US","country":"United States","bounding_box":{"type":"Polygon","coordinates":[[[-84.161625,35.849573],[-83.688543,35.849573],[-83.688543,36.067417],[-84.161625,36.067417]]]},"attributes":{},"full_name":"Knoxville, TN","name":"Knoxville","id":"6565298bcadb82a1","place_type":"city","url":"http:\/\/api.twitter.com\/1\/geo\/id\/6565298bcadb82a1.json"},"retweet_count":0,"created_at":"Thu Mar 31 05:00:02 +0000 2011","user":{"notifications":null,"profile_use_background_image":true,"default_profile":true,"profile_background_color":"C0DEED","followers_count":161,"profile_image_url":"http:\/\/a0.twimg.com\/profile_images\/1220577968\/RoadRunner_normal.jpg","is_translator":false,"profile_background_image_url":"http:\/\/a3.twimg.com\/a\/1301071706\/images\/themes\/theme1\/bg.png","default_profile_image":false,"description":"Cool & Calm Basically Females are the way of life and key to my heart...","screen_name":"FranklinOwens","verified":false,"time_zone":"Central Time (US & Canada)","friends_count":183,"profile_text_color":"333333","profile_sidebar_fill_color":"DDEEF6","location":"","id_str":"63499713","show_all_inline_media":true,"follow_request_sent":null,"geo_enabled":true,"profile_background_tile":false,"contributors_enabled":false,"lang":"en","protected":false,"favourites_count":8,"created_at":"Thu Aug 06 18:24:50 +0000 2009","profile_link_color":"0084B4","name":"Franklin","statuses_count":5297,"profile_sidebar_border_color":"C0DEED","url":null,"id":63499713,"listed_count":0,"following":null,"utc_offset":-21600},"id":53320627431550976,"coordinates":null,"geo":null}
it's just one line. I have more than 200GB which is compressed with gzip file. I guess the number at very first refers to its date. I'm not sure it's clear to you.