TL;DR; - best practices included below for both MATLAB and C-lang.
(Entering the HPC and distributed computing domains requires some new sort of self-discipline, as the toys get more and more complicated and the net-effects are not easily deconstructed to their respective root-causes if relying just on our previous purely [SERIAL] scheduling experience from common programming languages).
Never use shell time to seriously measure / compare a performance:
the more once your distributed concurrent processes reach some high number of openMP threads / MPI processes, setting the divisor N in the Amdahl's Law denominator.
1
processSPEEDUP = _______________________________
( 1 - SEQ_part ) <---- CONCURRENCY MAY HELP
SEQ_part + _________________
^^^ N <---- CONCURRENCY HARNESSED
|||
SEQ____________________________________ CONCURRENCY IMMUNE PART
Anticipations ought be realistic:
Never expect a SPEEDUP-dinner to be as FREE
as an overhead-naive
formulation of Amdahl's Law may seemed to have promised
Never use shell time to seriously measure / compare a performance:
the more once your distributed concurrent processes reach some high number of openMP threads / MPI processes, setting the divisor N in the Amdahl's Law denominator.
1
processSPEEDUP = ___________________________________
( 1 - SEQ_part ) <-- CONCURRENCY MAY HELP
SEQ_part + _________________ + CoST
^^^ N ^^^
||| ^ |||
||| | |||
||| +------------------ CONCURRENCY HARNESSED
||| |||
||| ||| A GAIN WITHOUT PAIN?
||| |||
||| ||| NEVER, SORRY,
||| ||| COMMUNISM DOES NOT WORK,
||| ||| ALL GOT AT THE COST OF
||| +++----- COSTS-OF-ALL-OVERHEADS
||| ++++++++++++++++++++++
||| +N job SETUPs
||| +N job DISTRIBUTIONs
||| +N job COLLECT RESULTs
||| +N job TERMINATIONs
|||
|||
SEQ____________________________________ CONCURRENCY IMMUNE PART
For more details on the impacts from add-on costs-of-overheads, may like to read this, or may jump straight into an interactive GUI-tool for a live, quantitative reality-based illustration on how small speedup any amount of CPU will bring on "expensively" distributed jobs, referenced in the trailer part of this post, where SPEEDUPs are shown
WHY they actually turn out to become SLOWDOWNs, on any amount of N
Q.E.D..
Plus there are some more details on actual constraints ( threading model related, hardware domain related, NUMA specific ), that altogether decide about the resulting scheduling and the achievable speed-up of the such declared flow of execution :
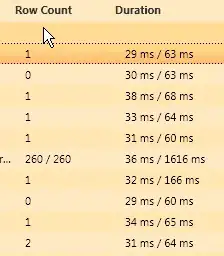
Independently from the details how a process may get accelerated by a distributed processing concurrency, the quality of measurement is discussed here.
Processes in C shall always use :
any high resolution timer available in the system. As a fast mock-up example, one may:
#include <time.h>
struct timespec {
time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
timespec diff( timespec start, timespec end ) {
timespec temp;
if ( ( end.tv_nsec - start.tv_nsec ) < 0 ) {
temp.tv_sec = end.tv_sec - start.tv_sec - 1;
temp.tv_nsec = end.tv_nsec - start.tv_nsec + 1000000000;
} else {
temp.tv_sec = end.tv_sec - start.tv_sec;
temp.tv_nsec = end.tv_nsec - start.tv_nsec;
}
return temp;
}
// /\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\
struct timespec start_ts, end_ts, duration_ts;
clock_gettime( CLOCK_THREAD_CPUTIME_ID, &start_ts );
// clock_gettime( CLOCK_PROCESS_CPUTIME_ID, &start_ts );
// clock_gettime( CLOCK_MONOTONIC, &start_ts );
// ____MEASURED-SECTION_START____________________
...
..
.
// ____MEASURED-SECTION_END______________________
clock_gettime( CLOCK_THREAD_CPUTIME_ID, &end_ts );
// clock_gettime( CLOCK_PROCESS_CPUTIME_ID, &end_ts );
// clock_gettime( CLOCK_MONOTONIC, &end_ts );
// _____SECTION__________
// duration_ts = diff( start_ts, end_ts );
// \/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/\/
Processes in MATLAB shall always use tic; ...; delta = toc;
MathWorks Technical Article arguments quite clearly on this subject:
In summary, use tic and toc to measure elapsed time in MATLAB, because the functions have the highest accuracy and most predictable behavior. The basic syntax is
tic;
... % … computation …
..
.
toc;
where the tic and toc lines are recognized by MATLAB for minimum overhead.

