Sobel filter is inhrently separable into X and Y dimensions in kernel execution. So one can scan only on X or only on Y dimensions or both of them in same kernel loop to achieve edge feature detection.
Using user azer89's soution here: Image Processing - Implementing Sobel Filter
I prepared this kernel:
__kernel void postProcess(__global uchar * input, __global uchar * output)
{
int resultImgSize=1024;
int pixelX=get_global_id(0)%resultImgSize; // 1-D id list to 2D workitems(each process a single pixel)
int pixelY=get_global_id(0)/resultImgSize;
int imgW=resultImgSize;
int imgH=resultImgSize;
float kernelx[3][3] = {{-1, 0, 1},
{-2, 0, 2},
{-1, 0, 1}};
float kernely[3][3] = {{-1, -2, -1},
{0, 0, 0},
{1, 2, 1}};
// also colors are separable
int magXr=0,magYr=0; // red
int magXg=0,magYg=0;
int magXb=0,magYb=0;
// Sobel filter
// this conditional leaves 10-pixel-wide edges out of processing
if( (pixelX<imgW-10) && (pixelY<imgH-10) && (pixelX>10) && (pixelY>10) )
{
for(int a = 0; a < 3; a++)
{
for(int b = 0; b < 3; b++)
{
int xn = pixelX + a - 1;
int yn = pixelY + b - 1;
int index = xn + yn * resultImgSize;
magXr += input[index*4] * kernelx[a][b];
magXg += input[index*4+1] * kernelx[a][b];
magXb += input[index*4+2] * kernelx[a][b];
magYr += input[index*4] * kernely[a][b];
magYg += input[index*4+1] * kernely[a][b];
magYb += input[index*4+2] * kernely[a][b];
}
}
}
// magnitude of x+y vector
output[(pixelX+pixelY*resultImgSize)*4] =sqrt((float)(magXr*magXr + magYr*magYr)) ;
output[(pixelX+pixelY*resultImgSize)*4+1]=sqrt((float)(magXg*magXg + magYg*magYg)) ;
output[(pixelX+pixelY*resultImgSize)*4+2]=sqrt((float)(magXb*magXb + magYb*magYb)) ;
output[(pixelX+pixelY*resultImgSize)*4+3]=255;
}
Indices were multipled with 4 here because they were interpreted as uchar array as kernel parameters. uchar is a single byte in OpenCL(at least for my system).
Here is a video of this:
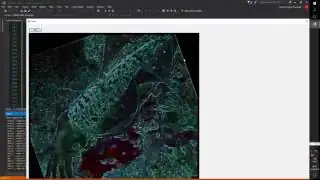
Sobel Filter Example
if it works for you too, you should accept azer89's solution. But this is not very optimized and may take 1-2 milliseconds for a low end GPU and even more with only a CPU for 1024x1024 image. The image data is sent to an OpenCL buffer(not image buffer) using a byte array(of C# language) and kernel launch options are:
- Global range = 1024*1024 (1 thread per pixel processing)
- Local range = 256 (this is not important)
- Buffer copy size 1024*1024*4 (bytes for rgba format)
also kernelx and kernely 2D arrays here were float so making them char could make it faster. Also you may check results(clamp, divide, ...) if result looks a lot more colorful than its expected. Host side representation/interpretation is also important to handle underflow and overlow of colors.