I have dataframe as below
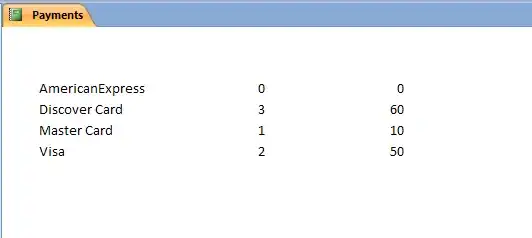
Every HH repeats exactly 3 times in a column. I have millions of such total records
I want to roll up data for each HH value in one row and delete remaining two rows for that HH.
For column A - take mode for the values for each HH , put it in a row. For column B- take mode for the values for each HH , put it in a row. For column C - take average of the values for each HH , put it in a row. For column D - take mode for the values for each HH , put it in a row.
I need to do this for all HH values which are in thousands in my dataframe.
output:
Thanks