I know having DEFAULT NULLS is not a good practice but I have many optional lookup values which are FK in the system so to solve this issue here is what i am doing: I use NOT NULL for every FK / lookup colunms. I have the first row in every lookup table which is PK id = 1 as a dummy row with just "none" in all the columns. This way I can use NOT NULL in my schema and if needed reference to the none row values PK =1 for FKs which do not have any lookup value.
Is this a good design or any other work arounds?
EDIT:
I have:
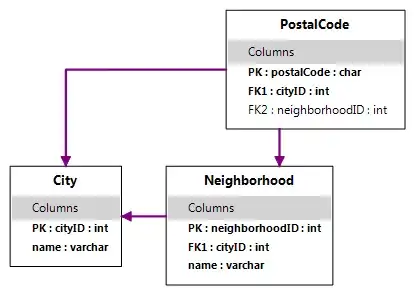
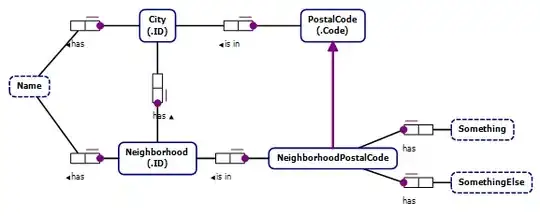
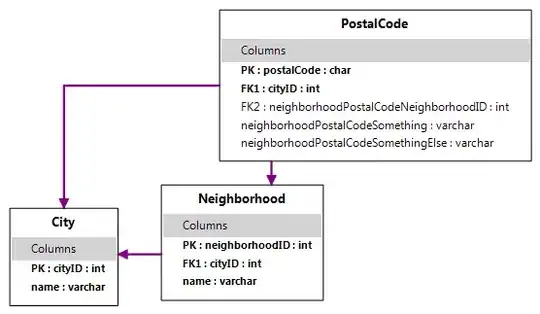
Neighborhood table
Postal table.
Every neighborhood has a city, so the FK can be NOT NULL. But not every postal code belongs to a neighborhood. Some do, some don't depending on the country. So if i use NOT NULL for the FK between postal and neighborhood then I will be screwed as there has to be some value entered. So what i am doing in essence is: have a row in every table to be a dummy row just to link the FKs.
This way row one in neighborhood table will be:
n_id = 1
name =none
etc...
In postal table I can have:
postal_code = 3456A3
FK (city) = Moscow
FK (neighborhood_id)=1 as a NOT NULL.
If I don't have a dummy row in the neighborhood lookup table then I have to declare FK (neighborhood_id) as a Default null column and store blanks in the table. This is an example but there is a huge number of values which will have blanks then in many tables.