As I understand the question, @Scarabee had it right. The answer depends on maximal cliques, but the bounty shows that the OP did not consider that a full answer. This answer pushes that through to assigning the HouseID.
library(igraph)
## Your sample data
Edges1 = read.table(text="ID.1 ID.2
A B
A C
B C
C B
C A
B A
D E
E F
F E
D F
E D
F D",
header=TRUE, stringsAsFactors=FALSE)
g1 = graph_from_edgelist(as.matrix(Edges1), directed=FALSE)
plot(g1)
MC1 = max_cliques(g1)
MC1
[[1]]
+ 3/6 vertices, named, from 8123133:
[1] A B C
[[2]]
+ 3/6 vertices, named, from 8123133:
[1] D E F
This gives the maximal cliques (the houses), but we need to construct the HouseID variable.
Edges1$HouseID = apply(Edges1, 1,
function(e)
which(sapply(MC1, function(mc) all(e %in% names(unclass(mc))))))
Edges1
ID.1 ID.2 HouseID
1 A B 1
2 A C 1
3 B C 1
4 C B 1
5 C A 1
6 B A 1
7 D E 2
8 E F 2
9 F E 2
10 D F 2
11 E D 2
12 F D 2
The outer apply loops through the edges. The inner sapply checks which clique (house) contains both nodes from the edge.
This provides the structure that the question asked for. But as @Scarabee pointed out, a node may belong to more than one maximal clique (house). That is not exactly a problem as the requested structure assigns the HouseID to edges. Here is an example with a node that belongs to two houses.
Edges3 = read.table(text="ID.1 ID.2
A B
A C
B C
D E
D A
E A",
header=TRUE, stringsAsFactors=FALSE)
g3 = graph_from_edgelist(as.matrix(Edges3), directed=FALSE)
plot(g3)
MC3 = max_cliques(g3)
Edges3$HouseID = apply(Edges3, 1,
function(e)
which(sapply(MC3, function(mc) all(e %in% names(unclass(mc))))))
Edges3
ID.1 ID.2 HouseID
1 A B 2
2 A C 2
3 B C 2
4 D E 1
5 D A 1
6 E A 1
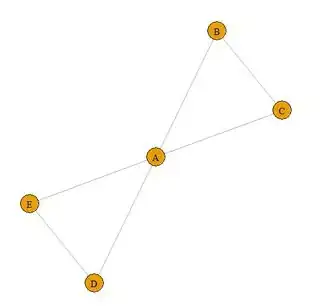
In this case, We can still assign a HouseID to each edge, even though the node A is in two different Houses. Notice that the edge A-B has HouseID = 2, but edge D-A has HouseD = 1. The HouseID is a property of the edge, not the node.
However, there is still a problem. It is possible for both ends of an edge to belong to two houses and one cannot assign a single house to the edge.
Edges4 = read.table(text="ID.1 ID.2
A B
A C
B C
D A
D B",
header=TRUE, stringsAsFactors=FALSE)
g4 = graph_from_edgelist(as.matrix(Edges4), directed=FALSE)
plot(g4)
MC4 = max_cliques(g4)
MC4
[[1]]
+ 3/4 vertices, named, from fbd5929:
[1] A B C
[[2]]
+ 3/4 vertices, named, from fbd5929:
[1] A B D
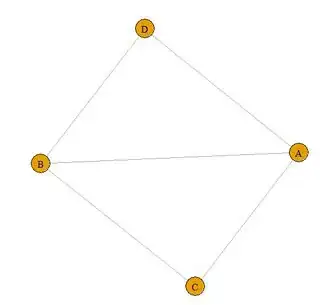
The edge A-B belongs to two maximal cliques. As @Scarabee said, the question is not actually well-defined for all graphs.

